Data Modeling for Scale with Cassandra
Reads and the perils of index tables.
I frequently see index tables in Cassandra being used to allow a One Source Of Truth. It’s important to remember when designing a truly distributed system relational algebra really doesn’t scale, and in memory joins will only get you so far (very little really). So as we often do in relational systems when we have an expensive dataset that is to expensive to calculate on the fly we create a materialized view. In Cassandra it’s helpful to think this way for all datasets that would require joins in a relational system.
Since Cassandra is write optimized lets take a look a typical social networking pattern with a “users stream” and see how we’d model with traditional normalization of data and how this looks in Cassandra with denormalized data.
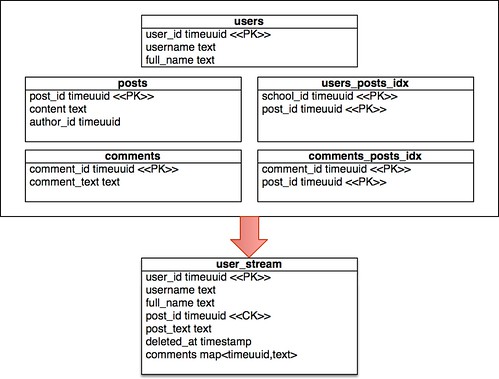
Instead of many many round trips to the database as we query each index table and then query the results of that index, then pulling data across many nodes into one query, which could take on the order of seconds, we can pull from one table and get results back in under 1 millisecond. Furthermore we can get optimized ordering on the post date and that users partition and get things back very quickly indeed, we’d have to order the comments client side, but even on the biggest comment threads that’d be a fast operation (if this won’t work there are other modeling options from here).
So about now you’re probably screaming bloody murder about how much work this is on updates and that updates for a 100 users following a post will result in 100 writes to the database, but I say so what. Cassandra is extremely write optimized and while there is a level at which this modeling may become expensive and require other concessions this will get you light years farther than the normalized approach, where the cost of reads will drag you down far before writing that much will (realize that most workloads are read more than write). But what about consistency? What if my update process only writes the post to 990 followers and then fails? Do I need batch processes to do consistency checks later?
Consistency through BATCH.
Cassandra offers the BATCH keyword. Batches are atomic, when they fail mid update, they will retry. If the node or client fall down (or both) a hint at the start of this process that allows other nodes to pick the retry of that batch up and finish the process.
If I assume a blog model and I want to display posts by tag and username. I can update both tables every time a post_title changes in one go, assuming I have the full post information, which is why putting this in the save path for posts is the perfect place for this to go.
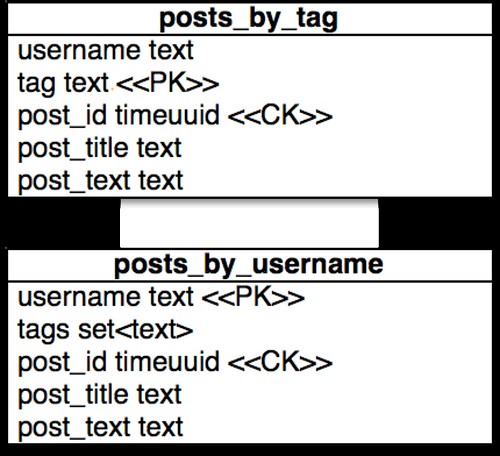
BATCH BEGIN
UPDATE posts_by_username SET post_title = 'Cassandra Consistency' WHERE username = 'rsvihla' AND post_id = '5f148a02-ccec-4c98-944d-6431cd86ad5c'
UPDATE posts_by_tag SET post_title = 'Cassandra Consistency' WHERE tag='Scaling' post_id = '5f148a02-ccec-4c98-944d-6431cd86ad5c'
UPDATE posts_by_tag SET post_title = 'Cassandra Consistency' WHERE tag='Cassandra' post_id = '5f148a02-ccec-4c98-944d-6431cd86ad5c'
APPLY BATCH
Now there is probably a practical size limit on batches so once you start having to update more than 100 rows at a time you want to consider batches of batches, which will lose you the easy consistency of one atomic batch, however, you will get that in the given batch size.
Summary
This is a quick tour of data modeling at scale and doing so with Cassandra. There are a lot more use cases and variants of this, but this is the basic idea.