Git guts: Merging and rebasing
Here we go again, explaining the internals of Git with the intention of helping you understand what you’re doing day-to-day. Last time I covered branches, HEAD, and fast-forwarding. Today we’ll dive into the guts of merging and rebasing.
Merging branches
You’ve probably merged before. You do it when you want the changes from one branch in another. The principal is the same in Git as it is most other source control systems, but the implementation differs.
Given the following commit structure, consisting of two branches created from the same commit, each with two commits after the branching occurred.
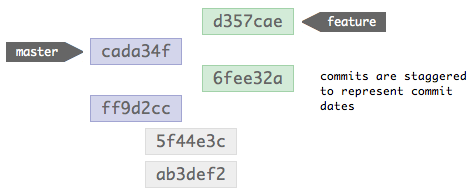
When these two branches are merged together, this is the structure that results:
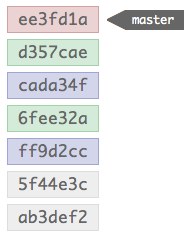
The top-most commit, the red one, is a new commit made by the merge; the merge commit is what reminds Git that a merge occurred next time it’s showing the history. This commit is special, as it contains multiple parent’s in it’s meta-data; these multiple parent’s allow Git to follow the two trees of commits that constituted the branches that were merged.
One difference in how Git handles merges compared to many other SCMs is that it preserves the commits that were made in both branches. In other systems merges are often represented as a single commit containing the squashed contents of all the commits that were made in the branch being merged in. Git doesn’t do this (by default, you can tell it to if you want), and therefore preserves all the commits just as they were made; this is quite nice, as it proves incredibly useful to be able to track the origin of changes beyond the point of a merge.
When you merge two branches, it’s interesting to know that none of the commits are altered in the process. Just bare this in mind for now, I’ll explain why this is good to know later.
After a merge, if you were to view the history, you’d see it shown like the previous example, commits in chronological order; the feature branch commits are interspersed between the master commits.
Yet no commits have been altered in the merge, so how are the commits in a different order? Well, they’re not, Git’s just showing you it in the order you expect it to be in. Internally the structure is still as below:
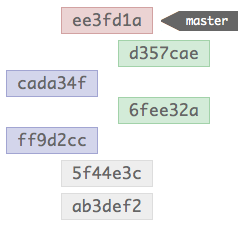
The merge commit instructs Git to walk the two trees while building the history, and it just displays the results in chronological order. This makes more sense if you recall that Git commits don’t hold differences like other SCM systems, instead they each contain a snapshot of the complete repository; while in another SCM the ordering of commits is vital — otherwise the diffs wouldn’t build a valid file — Git is able to infer order without affecting the repository contents.
Looking at it in commit order, you can quite easily see how Git flattens the history to be perceived as linear without ever having to touch any of the original commits.
What happens if there’s a merge conflict?
We’ve all dealt with conflicts in merging before. They typically happen when changes are made to the same file in two branches, in a way that cannot be easily merged (two people edit the same line, for example).
Git’s commit’s are immutable though, so how are the changes that you need to make to resolve these conflicts saved? Simple. The merge commit is a regular commit with some extra meta-data, and so it capable of containing changes itself; merge conflict changes are stored in the merge commit. Again, no changes necessary to the original commits.
Git objects, immutability, and rewriting history
A Git repository is comprised of objects. A file is a blob object with a name attached to it; if you have two files with the same content, that’s just two names to a single blob. A directory is a tree object, which is comprised of other trees and blobs. A commit is an object that references a tree object, which is the state of the repository at the time of committing.
To read more about git objects, I’d definitely recommend you read the Git community book.
Git objects are immutable. To change an object after it’s been created is impossible, you have to recreate the object with any changes made. Even operations that seem to modify objects actually don’t; commit --amend is a typical example, that deletes and re-creates the commit rather than actually amending it.
I mentioned that merges don’t rewrite history, and that it’s a good thing. Now I’ll explain why. When you rewrite history, you do so by making changes to commits that ripple up the commit tree; when this happens, it can cause complications when others merge from you. Given a series of commits, like so:
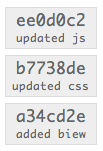
You then share these commits with another user.
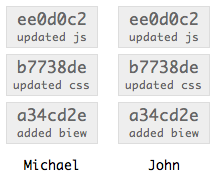
John now has Michael’s commits in his repository; however, Michael notices he’s made a typo in the first commit message, so he amends the commit message. The change in the message requires the commit be recreated. With that first commit recreated, the second commit now has an invalid parent reference, so that commit has to be recreated with the new reference; this recreation ripples it’s way up the tree, recreating each commit with a new parent. Michael has completely rewritten his tree’s history.
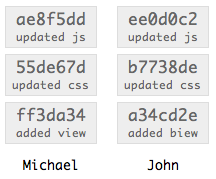
Notice all the commit hashes have changed in Michael’s repository, and John’s now don’t match. If Michael was then to make a new commit to his repository, and John tried to merge that change into his repository, Git would get very upset because the new commit would reference a commit that doesn’t exist in John’s repository.
The golden rule is: rewriting history is fine as long as the commits that will be affected haven’t been made public.
Rebasing
The purpose of a rebase is the same as a merge, to bring two tree’s of commits together. It differs in it’s approach. Rebasing is a seriously sharp tool. Very powerful, but pretty easy to cut yourself with it.
When you rebase one branch onto another, Git undoes any changes you’ve made in the target branch, brings it up to date with the changes made in the source branch, then replays your commits on top. This sounds quite strange, so I’ll go over it step-by-step.
You start with your diverged branches:

If you then rebase feature onto master, Git undoes the changes in master.

The history of both branches is now the same, master has been updated to reflect feature; the new commits that were made in master are now detached, floating in the repository without anything referencing them.
The next step is to replay the master commits onto the new structure. This is done one-by-one, and can sometimes result in conflicts that will need to be handled like any merge.
After replaying the repository will look like this:

The master branch commits are now on the top of the stack, after the commits from the feature branch.
You should recall that commits are immutable, and for changes to be made commits need to be recreated. A rebase is a destructive operation, as it has to rewrite commits to be able to work. In this case, the commits from feature have been unaffected, but the master commits have been assigned new parents (and thus rewritten). What’s also noticeable is there’s a lack of a merge commit, which isn’t needed because the commits have been integrated into the tree; any conflicts are stored in the amended commits, rather than in a merge commit.
The rewriting of commits in a rebase is what makes it a dangerous operation to perform on any branch that has already been pushed to the public (or specifically, that the changes affected by the rebase have already been pushed to the public). A rebase can cause problems upstream, like mentioned in the previous section.
Rebase has it’s place though. If you’re working locally and haven’t yet pushed your changes public, it can be a useful tool. Rebase can be used to pull in changes from upstream in the order that the upstream repository has them, and your local changes (that can be rewritten because you’re the only one with them) can be replayed on-top; this is a really easy way to keep your repository up-to-date with an authoritative source. You can also use Rebase to manage local branches that you don’t necessarily want polluting the history with merge markers.
When to rebase and when to merge?
Merge when you’ve already made changes public, and when you want to indicate that two tree’s have converged. Rebase pretty much any other time.
That’s it for this time. Same deal as last time, if you have anything you’d like me to cover I’ll nail it in the next one.