AutoMapper Git workflow – dealing with bugs/issues
Along with the switch of VCS to git came the ability to have much improved workflows that simply weren’t possible in CVCS like TFS or SVN. The nice thing about Git over CVCS is that because of its power, I can choose the workflow I want to use depending on my situation. Most, if not all of this comes from the fact that local branches are cheap, and the commit model of git.
A couple of the things I wanted to shoot for was a clean history and isolating work. With OSS development, I’m juggling a lot of different threads at once. Feature requests come in, bugs come in, new work is going on, pull requests come in, patch files/code detritus comes in, and I don’t want work on any one thing to conflict with the other.
And since work on each thing is very asynchronous in nature, I want to match my git workflow to the actual interaction workflow that I use in the real world. But first, let’s look at how we can visualize our local repository. That’s a huge step in dealing with different kinds of workflows.
Visualizing the repository
I prefer git extensions over gitk and git log –graph. Gitk is a bit of a pain to deal with, and git log attempts to use all the ASCII powers of the interwebs to display a graph of commits. For example, here’s the current AutoMapper commit graph (locally):
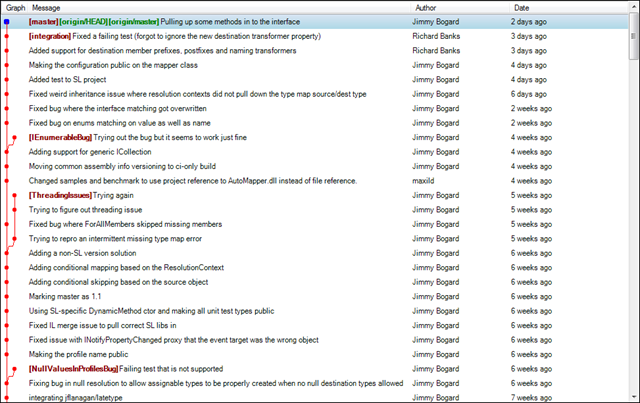
Note anything? A clean, linear history. I absolutely detest bizarre, convoluted histories, where I see a tangled web of commits. I have a few different workflows, but all start with a basic rule:
Always branch before doing ANY work.
Because branches are so, so cheap in git, branches become THE way to create parallel workflows.
</p>
Bug Workflow
When I get an issue from CodePlex, twitter, the mailing list or anything, I want to create a workflow that allows me to try and reproduce the issue, but without messing up the mainline master branch. Many times, I’ll have conversations back and forth with other folks over the course of days or weeks, as I try and fix an issue. In those cases, that branch can potentially stick around for a long time and NEVER come back to the master branch.
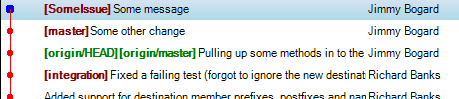
So first things first: An issue comes in, so I create a branch:
git co –b “SomeIssue”
This builds the following picture in my local repo:

Remember, a branch is really just a lightweight, named pointer to a commit. The “git checkout –b” means to create a branch and checkout that branch immediately. “git checkout” is analogous to the “svn switch” command, except git branches are MUCH simpler than SVN branches.
Next, I make some commit locally to that branch, and usually do something like:
git add .
git commit –m “Some commit message”
This now produces the following picture:

At this point, I usually go two routes. If I can fix the actual issue, then I’ll want to integrate my changes back to the master branch. If I can’t reproduce it, need more information or whatever, I’ll just leave it alone. The really cool thing is that it doesn’t matter. At any time, I can checkout master, start a new branch and continue on. Let’s see what it looks like if there are additional changes that happen on the master branch:

We now see that master is basically ahead of SomeIssue. I might have other branches hanging around as well.
So let’s suppose I want to integrate the SomeIssue branch back to master. Now, if there have been upstream changes and changes locally to master, I’ll want to do a “git pull –rebase”. This is similar to an “svn update”, and “get latest” in TFS. However, there aren’t any changes, so what I really want to do is a rebase, from the SomeIssue branch to the master branch:
git rebase master
This results in the following history now:
Rebase is different than merge in that it re-applies commits from one branch to another. What I’ve done here is basically re-play the commits from the SomeIssue branch onto the master branch, so that there is a clean, linear history.
With that done, I’ll do the normal local build. Finally, I’ll checkout master and rebase or merge, the result is the same (a fast-forward merge):
git checkout master
git rebase SomeIssue
And now my history looks like this:

Now that my branch is “done”, I’ll delete that branch:
git branch –d SomeIssue
And my history now shows SomeIssue is gone:

Because a branch is merely a lightweight pointer to a commit, it’s really no big deal to delete a branch, as the creation and deletion of branches does NOT affect the commits in any way.
Now that my branch is integrated into a clean timeline (without any merge commits), I can push master back to origin.
So that’s it, my basic bug workflow is:
- (from master): git checkout –b “SomeIssue”
- do work, git add and git commit –am “Some commit message”
- git checkout master
- git pull –rebase
- git checkout SomeIssue
- git rebase master
- git checkout master
- git rebase SomeIssue <- this is just a fast-forward merge at this point
- git push origin master
- git branch –d SomeIssue
This workflow gives me a couple big advantages. First, I can work on bugs/issues that may never have a resolution, and that’s just fine. In fact, in the original history shown at the top, you can see a couple of branches that went off and never came back. They may never in the future either, and that’s okay.
Several times, I’ll be working on one bug, stop, and work on another. The first bug might have failing tests/compilation, but all that work is on a branch so it doesn’t conflict with other parallel work.
And now that I have two bogus commits in my timeline, I’ll just do a “git reset –hard HEAD~2” and rewind time like nothing happened 🙂
For more information about how branches and rebase works, check out the free online Pro Git book: