Queues are still queues
Recently, we’ve started migrating our application to more of a message-based architecture. This will be part of a bigger series on migrating to a messaging-based architecture, but one rather funny (or not funny, since we were in production) side effect of the nature of queues hit us the other week.
What is a queue? A queue is a FIFO (First-in, First-out) data structure, where the item pulled from the queue is the oldest message in the store. Standing in line at a Starbucks is a queue, as the first person to arrive in line is the first person served. Unless some yuppie jerk cuts, of course.
We first introduced queuing into our system by translating incoming files FTP’d from 3rd-party vendors as a series of commands and events. We separated these into two queues:
- Commands
- Events
As we started using messaging more and more, we utilized events and commands to separate our system concerns into separate contexts. However, we left things as these two queues. We had one process that needed its messages processed rather immediately (within 1-2 minutes):

The FooSomething command needed to be processed fairly quickly, but because they weren’t triggered very often (2-3 per minute), it wasn’t a problem. Until we introduced a process that ran once a day, but dumped 10s of thousands of other commands on the same queue:
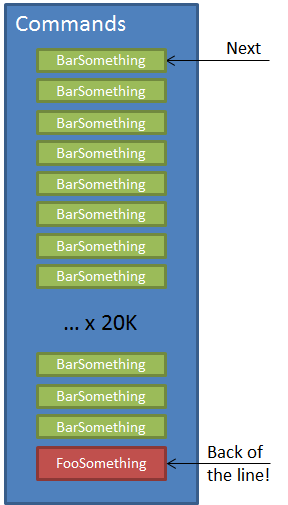
So if FooSomething needs to be processed within 1-2 minutes, and the other messages are in its way, its SLA gets trashed. In the Starbucks example, it’s as if we have two types of customers – preferred and normal. Preferred customers need to get their coffee within 30 seconds, but we’ve limited the number of preferred customers so that if we have normal staffing levels, everything should work fine.
We then changed Starbucks to also sell hamburgers, Chinese food, prescription drugs and used cars. Each of these has vastly different demands and wait times associated processing each request. But we went ahead and dumped them all into the same line to be processed. Our preferred customer winds up pissed that all these folks that have nothing to do with coffee are now standing in their line!
It turns out we just designed our queues wrong. Instead of focusing on what the message conceptually represented (commands vs. events), we should instead have split the queues based on SLA. We can up the worker threads in NServiceBus (equivalent to having more cashiers), but that won’t help FooSomething get to the front of the line faster when there are so, so many messages in front.
If we separated our queues and workers based on SLA, we would instead have a picture like:
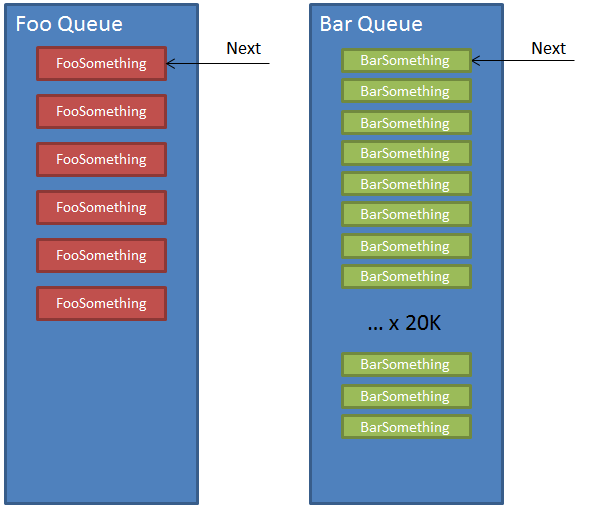
The SLA for the FooQueue is 1-2 minutes, while the BarQueue is much higher, around 2 hours or so. If we split our queues based on the SLA for the messages in the queue, we can now appropriately assign resources to each listener (NServiceBus host). But forcing everyone to go through one single line inadvertently allows the volume of different messages to affect the throughput of my message.
This is more of the food court model. Whatever food type you want, you go to that line. If one line stacks up, we can assign more cashiers/workers to that line to make sure everyone gets served in a timely fashion.
Lesson learned – a queue is a queue, and behaves exactly as such.