Feature branches and toggles
I’m a huge Martin Fowler fan, but one bit of advice I still can’t understand is the recommendation to eschew feature branches for feature toggles. The argument against feature branches are not just merge problems, but semantic merge problems, such as a method rename. This leads to a fear of refactoring, and
Indeed I see this as the decisive reason why Feature Branching is a bad idea. Once a team is afraid to refactor to keep their code healthy they are on downward spiral with no pretty end.
In practice, however, I’ve rarely seen this to be the case. In functional teams (i.e., not dysfunctional), refactorings aren’t done in isolation and without communication, no matter what the branching strategy. If you’re performing a large rename or big shift in design, or even a little shift that isn’t just adding functionality, you’re communicating, asking questions, getting feedback, whiteboarding and so on. If I’m surprised about refactoring based on a merge, this is a failure in communication from the team.
The picture Fowler shows is a Big Scary Merge:
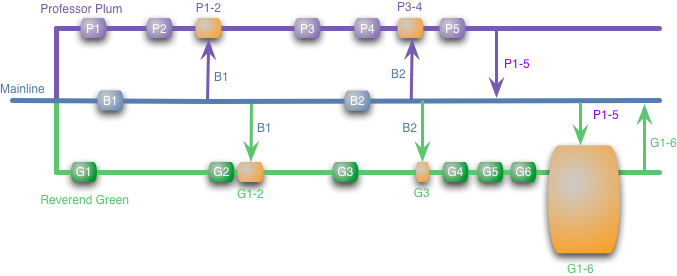
The idea here is that the P branch, merged in, makes it difficult for the G branch to come in. But this assumes a faulty strategy – that large refactorings happen solely in feature branches. But for larger refactorings, these can be thought of features themselves (or technical debt stories, if that’s your cup of tea). I tend to have these in their own branch, once discovered, so that that refactoring makes it in as its own merge commit, or set of commits, to the mainline branch.
The alternative is a Continuous Integration/Delivery picture, where developers are more or less working straight off of the mainline branch:
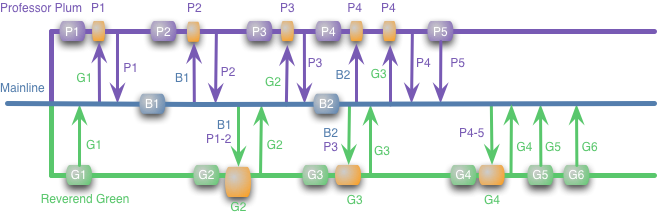
From my experience, without an effective sandbox, commits actually become less frequent, as the pressure is on to have a commit “deployable”. I’m all in favor of deployable commits, but my rule is that all commits to the mainline branch are deployable. What you do in your feature branch is just Work In Progress, and I’d much rather you optimize for small steps. In my branches, I often don’t even care if tests pass, I’m just tagging mental checkpoints.
In order to mitigate merge risks, I simply make sure I don’t have long-running branches. A week is about the maximum I allow, and past that, I look at doing feature toggles. Feature toggles are actually quite useful for at least getting code in production and not turned on yet. In fact, many systems I work on have features that turn “on” at a certain date/time, so it’s rather straight forward to just code that in, deploy it early, and modify the dates for testing.
But for refactorings, those aren’t discovered through a merge if we’re doing things right. And they’re not piggy-backing a feature if we’re trying to mitigate the merge risk.
These are just my experiences however, and I can understand that there must be anecdotal reasons of folks seeing problems with feature branches (and not just long-lived branches or mixed-use branches). If you’ve seen problems, let me know in the comments!