Reducing NServiceBus Saga load
When presented with concurrency issues with NServiceBus sagas, you’re generally presented with two options:
- Relax the transaction isolation level
- Reduce worker thread count, forcing serialized processing of messages</ul> Both of these are generally not a great solution, as neither actually tries to solve the problem of concurrent access to our shared resource (the saga entity). The process manager pattern can be quite powerful to solve asynchronous workflow problems, but it does come with a cost – shared state.
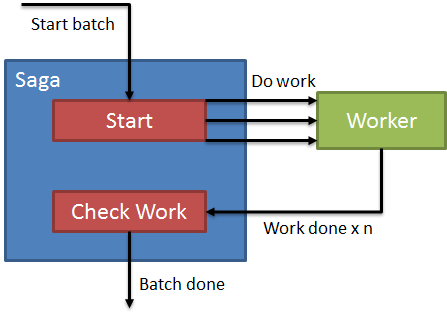
Suppose we had a process that received a batch of operations to perform, and needed to notify a third party when the batch of operations is done. It looks like we need something to keep track of what’s “done” or not, and something to perform the work. Keeping track of work to be done sounds like a good fit for a saga, so our first attempt might look something like this:
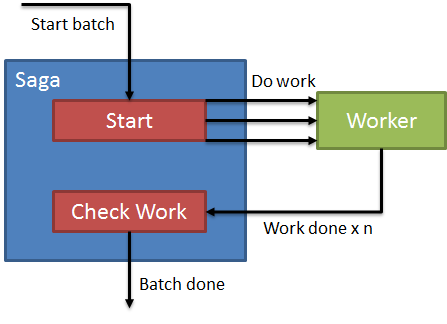
Our process will be:
- Send message to start batch saga
- Send messages to workers for each item of work to be done
- Listen for work done messages, check if work done
- If work done, send batch done message</ol> The problem with this approach is that we’re creating a shared resource for our work to be done. Even if we do something completely naïve for tracking work:
Even if we’re only tracking the count of work completed (or decrementing a counter, doesn’t matter), the problem is that only one “work done” message can be processed at a time. Our actual work might be isolated, letting us scale out our workers to N nodes, but the notification of done still has to get back into a single file line for our saga. Even if we up the worker count on the saga side, modifications to our saga entity must be serialized, done only one at a time. Upping the number of workers on the saga side is only going to lead to concurrency violations, exceptions, and an overall much slower process.
###
Reduction through elimination
I picture this as a manufacturing facility supervisor. A batch of work comes in, and the supervisor hands out work to workers. Can you imagine if after each item was completed, the worker sends an email to the supervisor, with their checklist, to notify they were done? The supervisor would quickly become overwhelmed by the sheer volume of email, to be processed one-by-one.
We need to eliminate our bottleneck in the supervisor by separating out responsibilities. Currently, our supervisor/saga has two responsibilities:
- Keep track of work done
- Check if work complete</ol> But doesn’t a worker already know if work is done or not? Why does the worker need to notify the supervisor that work is done? What if this responsibility was the worker’s job?
Let’s see if we can modify our saga to be a little bit more reasonable. What if we were able to easily update each item of work individually, separate from the others? I imagine in my head a tally sheet, where each worker can go up to a big whiteboard and check their item off the list. No worker interferes with each other, as they’re only concerned about their own little box. The saga is responsible for creating the initial board of work, but workers can update themselves. At this point, our saga starts to look like: [<img style="border-left-width: 0px;border-right-width: 0px;border-bottom-width: 0px;padding-top: 0px;padding-left: 0px;padding-right: 0px;border-top-width: 0px" border="0" alt="image" src="https://lostechies.com/content/jimmybogard/uploads/2014/02/image_thumb6.png" width="517" height="433" />](https://lostechies.com/content/jimmybogard/uploads/2014/02/image6.png) Our saga now only checks the sheet, which doesn’t block with a worker updating it. Our saga now only reads, not writes. In this picture, we still get notifications for every single worker, that still has to go in a single queue. We can modify our saga slightly by instead of getting notifications for every worker, we register a timeout message. Does the “batch done” message need to go out _immediately_ after the last worker is done? Or some time later? If, say, we only need to notify batch done, we can use timeouts instead, and simply poll every so often to check for done. With timeouts, we’re greatly reducing network traffic, and potentially, reducing the time between when workers are _actually_ done from when we _notify_ that we’re done. Suppose we have 100K items to send to our workers. That means we’ll have 100K “Work Done” messages needing to be processed by our saga. How long will it take that to process? Instead, a timeout message can just periodically check done-ness: [<img style="border-top: 0px;border-right: 0px;border-bottom: 0px;padding-top: 0px;padding-left: 0px;border-left: 0px;padding-right: 0px" border="0" alt="image" src="https://lostechies.com/content/jimmybogard/uploads/2014/02/image_thumb7.png" width="530" height="433" />](https://lostechies.com/content/jimmybogard/uploads/2014/02/image7.png) We can even relax our constraints, and allow dirty reads on checking the work. This is now possible since recording the work and checking the work are two different steps. We’ve also greatly reduced our network load, and provided predictability into our SLA for notifying on work done. ### Reducing load To reduce load in our saga, we needed to clearly delineate the responsibilities. It’s easy to build a chatty system and not see the pain when you have small datasets or no network load. Once we start imagining how the real world tackles problems like these, the realities of network computing become much more obvious, and a clear solution presents itself. In this case, a supervisor receiving notifications for everything and keeping track of a giant list just wouldn’t scale. By going with a lower-intensive option and trading off immediate notification for predictability, we’ve actually increased the accuracy of our system. It’s important to keep in mind the nature of queues as FIFO systems with limited concurrency, and sagas having a shared resource, and what this implies in the workflows and business processes you model.
- Listen for work done messages, check if work done
- Send messages to workers for each item of work to be done