Cassandra Query Patterns: Not using the “in” query for multiple partitions.
So lets say you’re doing you’re best to data model all around one partition. You’ve done your homework and all you queries look like this:
SELECT * FROM my_keyspace.users where id = 1
Over time as features are added however, you make some tradeoffs and need to start doing queries across partitions. At first there are only a few queries like this.
SELECT * FROM my_keyspace.users where id in (1,2,3,4)
You’re cluster is well tuned so you have no problems, but as time goes on your dataset increases and users are doing bigger searches across more users.
SELECT * FROM my_keyspace.users where id in
(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23)
Now you start seeing GC pauses and heap pressure that leads to overall slower performance, your queries are coming back in what happened?
Imagine the contrived scenario where we have a partition key with the values A,B,C with 9 nodes and a replication factor of 3. When I send in my query that looks like SELECT * FROM mykeyspace.mytable WHERE id IN (‘A’,’B’,C’) the coordinator has to do something like:
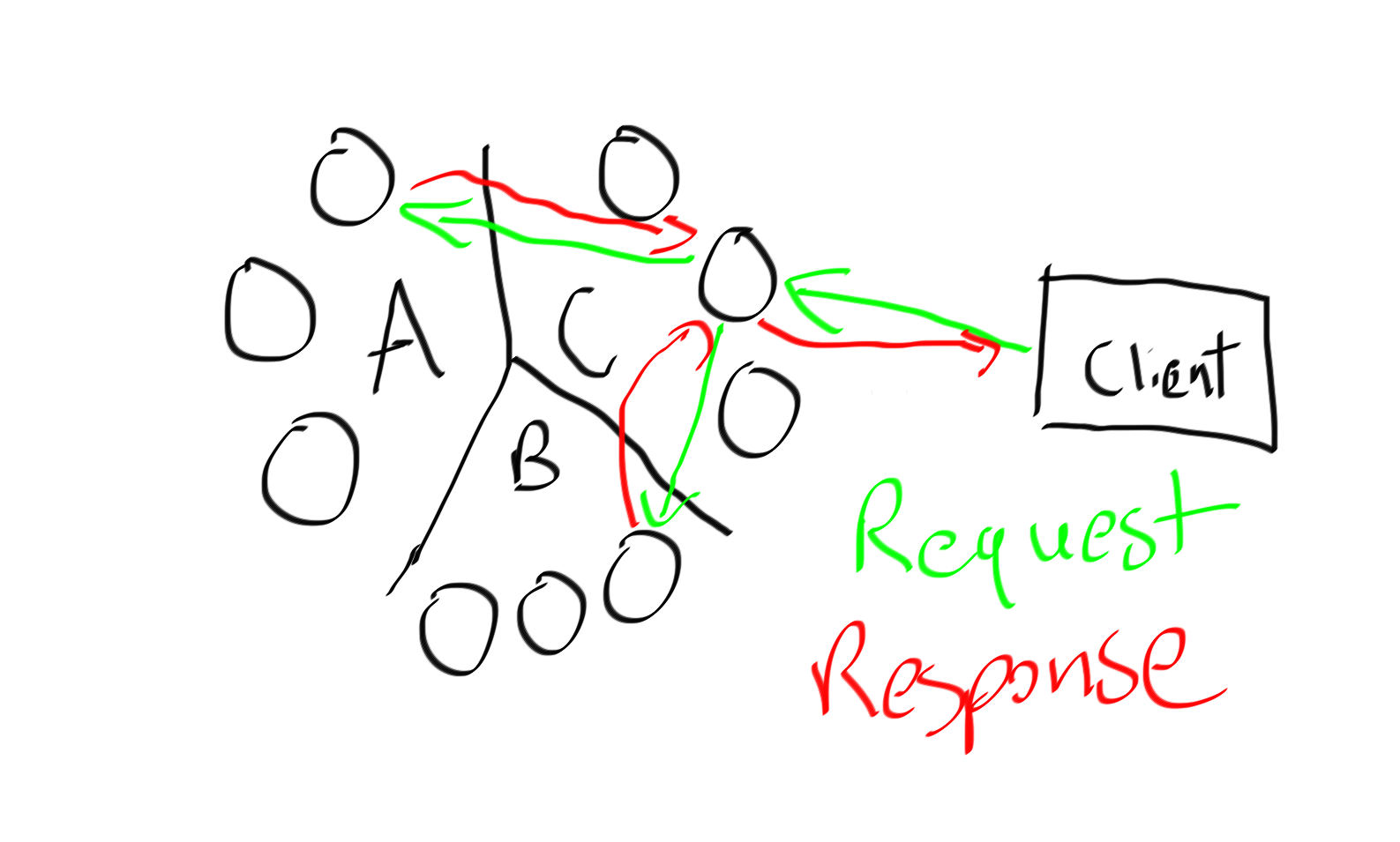
In practical terms this means you’re waiting on this single coordinator node to give you a response, it’s keeping all those queries and their responses in the heap, and if one of those queries fails, or the coordinator fails, you have to retry the whole thing.
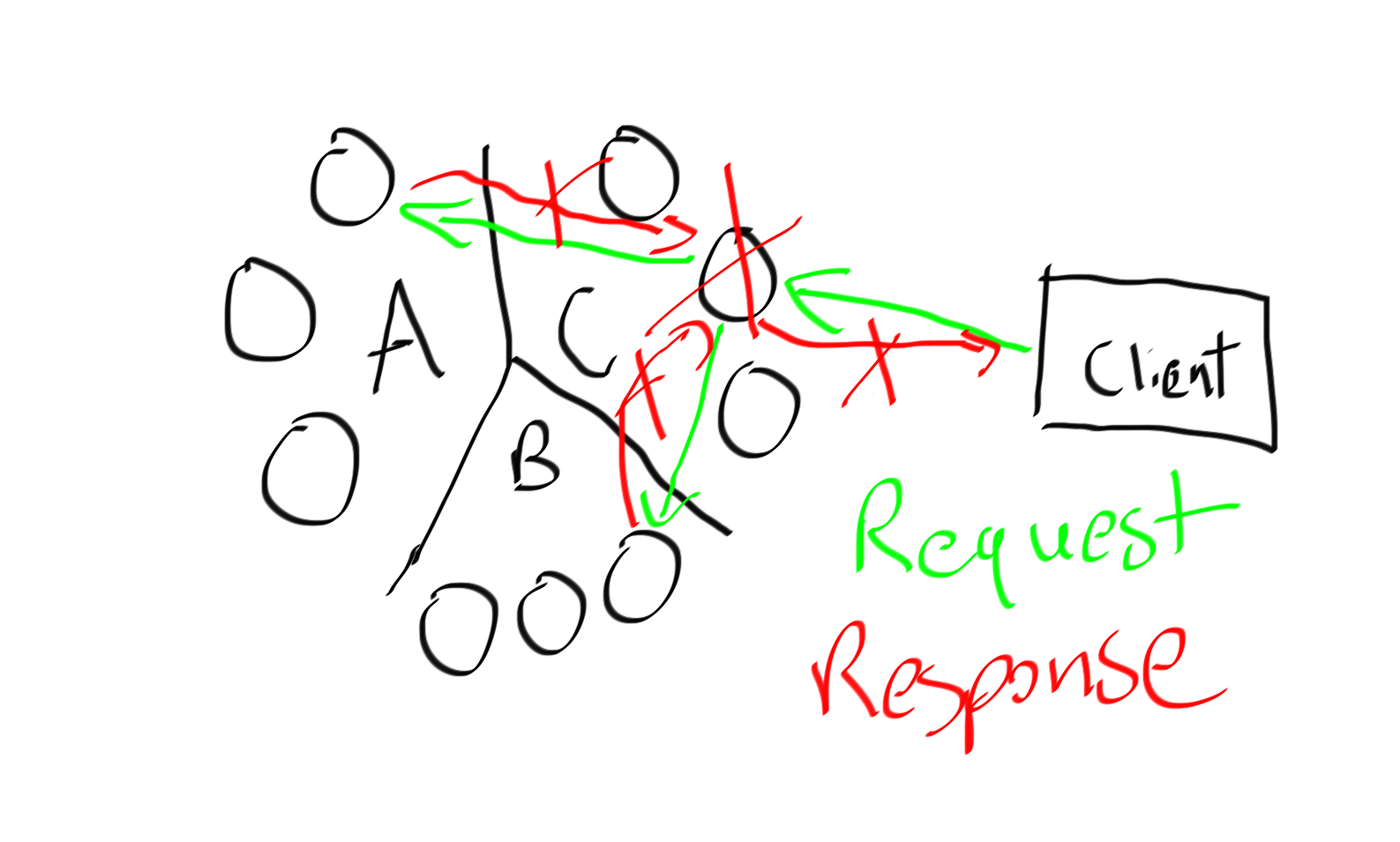
This means a dead coordinator node means the entire query result is gone. Instead of trying to approach this like a relational database let’s embrace the distributed nature of Cassandra and send queries directly to the nodes that can get the best fastest answer.
In Java
PreparedStatement statement = session.prepare(
"SELECT * FROM tester.users where id = ?");
List<ResultSetFuture> futures = new ArrayList<>();
for (int i = 1; i < 4; i++) {
ResultSetFuture resultSetFuture = session.executeAsync(statement.bind(i));
futures.add(resultSetFuture);
}
List<String> results = new ArrayList<>();
for (ResultSetFuture future : futures){
ResultSet rows = future.getUninterruptibly();
Row row = rows.one();
results.add(row.getString("name"));
}
return results;
In C#
PreparedStatement statement = session.Prepare("SELECT * FROM tester.users where id = ?");
List<String> names = new List<String>();
for (int i = 1; i < 4; i++)
{
var resultSetFuture = session.ExecuteAsync(statement.Bind(i));
resultSetFuture.ContinueWith(t =>
{
var result = t.Result.First();
var name = result.GetValue<String>("name");
names.Add(name);
});
resultSetFuture.Wait();
}
return names;
Now doing a retry requires only one small fast query, you’ve eliminated the single point of failure.
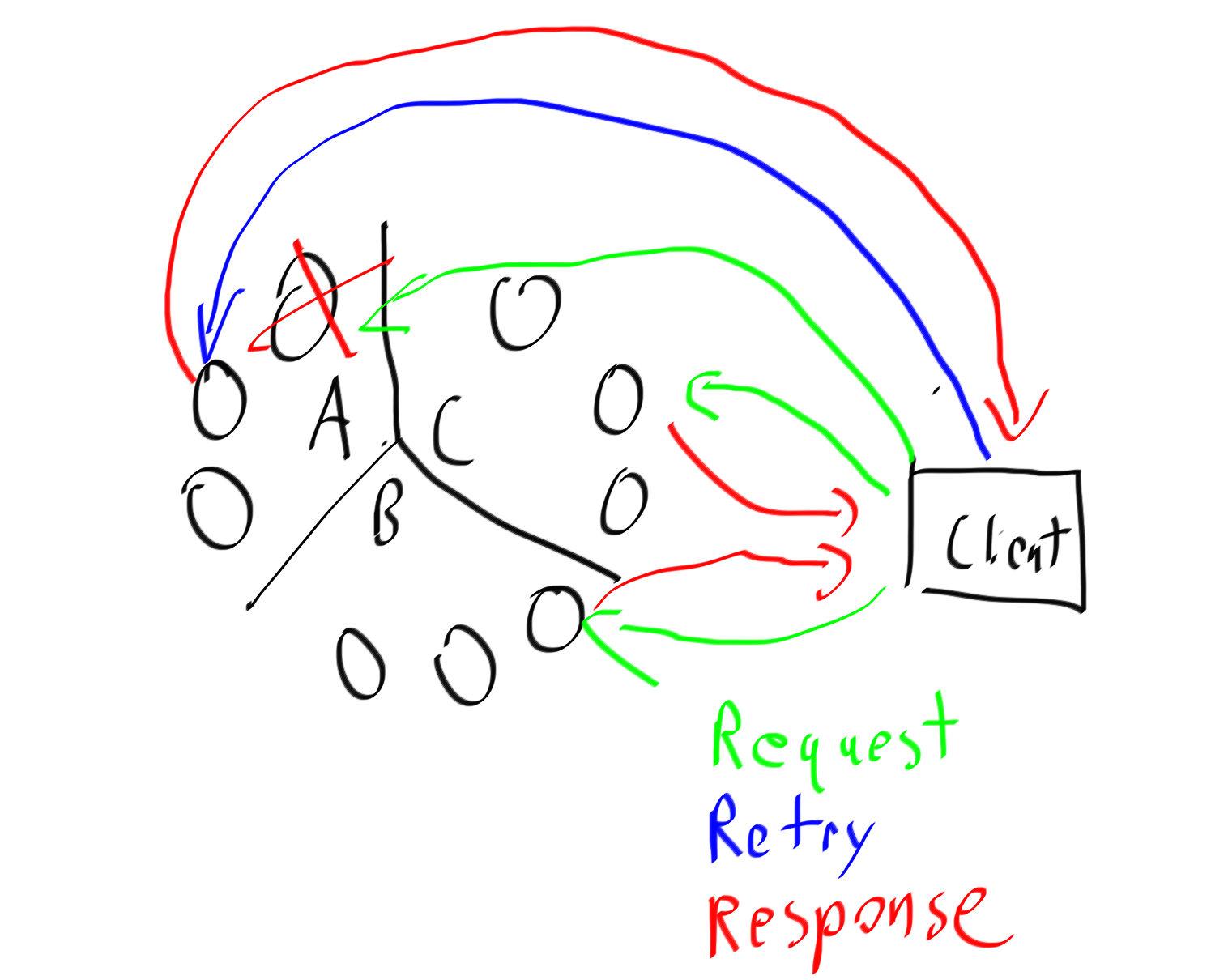
With separate queries you get no single point of failure, faster reads, less pressure on the coordinator node, and better performance semantics when you have a nodes failing. It truly embraces the distributed nature of Cassandra.
The “in” keyword has it’s place such as when querying INSIDE of a partition, but by and large it’s something I wish wasn’t doable across partitions, I fixed a good dozen performance problems with it so far, and I’ve yet to see it be faster than separate queries plus async.
A note about distributed thinking
This and my ‘no batch’ blog post really drive a bigger discussion about distributed thinking. Most things that don’t really work as well in a distributed database as people think they should, bulk loading via batch, in queries, and ‘rollbacks’ are left over vestiges from a single machine thinking.
This highly consistent single machine world is easy to reason about, but it doesn’t scale easily, and has single points of failure, and when you do make the tradeoffs needed to scale, you find features like “in” queries don’t scale unless they happen to be all be on the same machine (like Cassandra). You’ll find when you try and scale highly consistent single machine technologies via sharding you run into the same problem set as we have with distributed databases, only without appropriate tools.
So embrace continuous availability, multiple replicas, and leave behind yesterday’s approaches.