Event Sourcing and System of Record: Sane Distributed Development In The Modern Era
No matter the message queue or broker you rely on whether it be RabbitMQ, JMS, ActiveMQ, Websphere, MSMQ and yes even Kafka you can lose messages in any of the following ways: {#8e26}
AKA the typical distributed systems problem set.
Despite these data safety issues, messaging remains a popular pattern for the following reasons:
All of these advantages are BIG wins and not easily shrugged off.
So how does one minimize the bad and get all that messaging goodness? There are several strategies that companies use but I’ll cover the most common approach I see.
System of Record
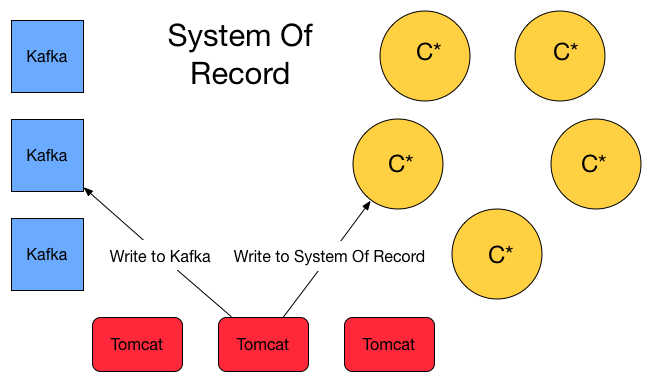
Duplicate writes to the messaging system and the System of Record
In the above diagram I’m showing a variant of the common approach where I chose to write to the system of record while writing to my broker of choice which is Kafka. For the system of record I persist every message to database (Cassandra in this case which is often called C*) in a table called events.
Most often these events are using Event Sourcing or what is sometimes called a Ledger Model.
create table my_keyspace.events (time_bucket timestamp, event_id timeuuid, ts timestamp, message text) # use a reasonably small time resolution to keep events under 100k per timestamp
Replay {#6519}
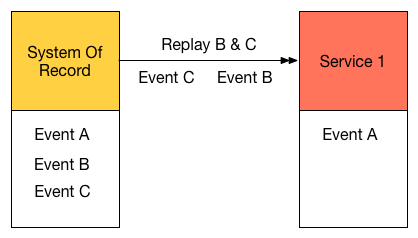
Replaying Events C and B
The ability to replay those events lies primarily in the following code. While the replayBucketStrategy is just a Java 8 Consumer so it’s up to the reader to build something useful with that. This sample makes clear the strategy used for replay.
public class SystemOfRecord {
private final Consumer replayBucketStrategy;
//15 second increments for the time bucket. This can be as
// large or as small as needed for proper partition sizing private final long bucketIncrement = 15000;
public SystemOfRecord(Consumer<Date> replayBucketStrategy){
this.replayBucketStrategy = replayBucketStrategy;
}
public void replayDateRange(Date start, Date end)
Date incrementedDate = new Date(start.getTime());
//check to see if the incremented time is greater
// than the end time.
while(incrementedDate.getTime()<end.getTime())
//take the date as an arugment for which cassandra
// table to query for messages
this.replayBucketStrategy.accept(incrementedDate);
final long time = incrementedDate.getTime();
//add bucket increment to get the next bucket
incrementedDate = new Date(time + bucketIncrement);
}
}
}
This code will allow you to over a given range of data to resend a given series of time buckets and their corresponding messages ( note I chose to not include the end range as one of the buckets that are replayed, you may change this to suit your preferences).
Handling Duplication {#19c1}
Your downstream systems have to be able to handle duplication with this scheme, or the process will become completely manual where you’ll have to manually compare which events have been replicated and which have not.
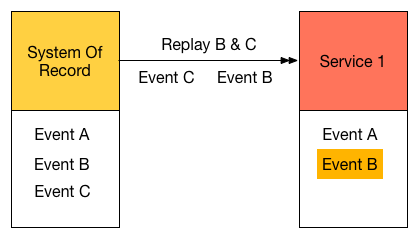
Service 1 Already has Event B
This gives us one two choices, Idempotent Services or Delete+Reload
Idempotent Services {#8cbb}
Advantages: Safe, easy to replay. You should be doing this anyway in distributed systems.
Disadvantages: More work than the alternatives. Have to think about your data model and code. Have to have some concept transaction history in your downstream systems.
Read more about is almost anywhere on the web, you can start with a short summary here. In summary you design your service around these replays of messages, and it’s trivial to build up from there.
In traditional idempotent designs you often have a threshold of how long a retry can occur. If you use an immutable data model like we talked about earlier such as Event Sourcing, this becomes pretty easy.
Delete + Reload
Advantages: Low tech, easy to understand.
Disadvantages: This is an implied outage during the delete phase.
Simple, delete all your data in the downstream service, and then replay all the events from the system of record. The downside of course is that you have no data while this is occuring, and it can take some very long period of time to wait on. On the plus side there are lots of problem domains that fit into this downtime mode. The downside is there are a lot more than do not, and cannot afford to be down at all. This is in no small part why you see Idempotent Services and Event Sourcing becoming so popular.
Wrap Up
I hope this was a helpful introduction to safer messaging. While on the surface this seems simple enough, as you can see there is a lot of nuance to consider and there always is with any distributed system. My goal is not to hide the complexity but highlight the parts you have to think about and simplify those choices from there.