- After starting the process, wait a couple of seconds and then make sure the thread is running. If not, there’s no need to go any further.
- Redirect the stderr and stdout from the thread to the console, so that if there is a problem I’ll see what the problem is rather than just getting a stupid popup in the system notification area.
-
Step 1 is to find the correct link to click. You are presented with 2 options – a very large link to a PDF document, or a very small link ‘click here to acknowledge’. Basic web and usability guidelines say that you should use larger targets for more important operations, and that using the word ‘here’ or ‘click here’ as a link are bad practice. (see item #2 at http://www.useit.com/alertbox/designmistakes.html Jakob Nielsen is a well-known author of several books on usability.)
-
When clicking on the correct link, a page is presented that only works in Internet Explorer. Several of my co-workers don’t use Windows at all, so using Internet Explorer requires them to go to another machine.
-
When the page is presented, Internet Explorer warns that some items are the page are secure and some are not. I would call this a bug.
-
When clicking on the correct link in Internet Explorer, the document to be acknowledged is presented, but the “acknowledge” button is hidden at the bottom.
-
After clicking the acknowledge button, a dialog is shown that has wording including a font change tag (I don’t have the exact text here, but it was something like “You have acknowledged that you have read the <font size=”4″>Policies of acknowledgment </font>….”
-
The dialog just mentioned ends with the phrase “Click OK to continue?” and the dialog has 2 buttons, OK and Cancel. It is unclear what the system would do if one pressed Cancel.
-
The system indicates success by removing the ability to read the document you just acknowledged, rather than by listing all the company policies and indicating those that had been acknowledged and those that had not.
- Green only – all builds are good, nothing in progress
- Green + Yellow – all builds are good, build in progress
- Red only – at least one build is broken, nothing currently building
- Red + Yellow – at least one build broken, build in progress.
Headspring sponsoring Open Source Hackathon
In conjunction with Pablo’s Fiesta, an open-space development conference being held in Austin September 30-October 2, Headspring will be sponsoring an Open Source Hackathon at our offices on Sunday October 2nd from 1 PM to 6 PM. Over 150 developers from all over the United States and beyond are coming to Austin for 3 days of ‘sharpening the saw’, and the Los Techies Crew realized that with all that brainpower in one place, we ought to be able to do some concentrated work on the open source tools we all use so much.
If you’re attending the Fiesta, or even if you aren’t, feel free to come by the Headspring offices on Sunday to learn more about how open source software is written, ask questions about tools you’re using or would like to use, or even kick-start a new open-source project! Please bring a laptop if you can!
Get more details by going to the Google Group for Pablo’s Fiesta Hackathon.
Open Source Hackathon at Pablo’s Fiesta
This is something several of the Los Techies crew have been talking about doing as a little something extra around Pablo’s Fiesta. The idea is that with so much brainpower all in one place, we might be able to do something for the Open Source projects that we all use and love, and learn a little something along the way. So far we have a couple of different ideas. Our first idea was to have a ‘bugsmash’ where people get together and work on fixing some bugs in people’s favorite OSS packages. Or it could be that folks have an idea for an OSS project that doesn’t exist yet, and maybe people would like to help out and get something kick started. Along the way, we could have people who are experienced working in open source help guide people who would like to get involved but who don’t have the experience yet. There would be lots of opportunities for working in all different kinds of areas – whether it is simple git/github/bitbucket workflows, an introduction to open source project etiquette, or diving deep into certain technologies you’ve always wanted to use, but don’t get a chance to use at work.
So that’s the plan (such as it is) for now. We know we have a few of the Los Techies crew interested, and we’ve talked to some folks about securing some working space close to the conference site. Tentatively, we’re thinking this would be either Saturday night or Sunday afternoon. In either case, we could have food involved, beer, whatever!
I’ve set up a Google group specifically for this, so please join that if you are interested and want to learn more details.
http://groups.google.com/group/pablos-fiesta-hackathon
By the way – details for Pablo’s Fiesta are at http://lostechies.github.com/fiesta/
Tracking down a strange issue with WatiN and IIS Express
In my current project, we have a system that runs our Watin tests using NUnit. We also want to run the tests in our CI build, so we start IIS Express in a [SetUpFixture]. Today I was doing my check in dance and none of the watin tests were passing. It appeared to be a problem with IIS Express starting up, but it was completely unclear what the problem was. I would get a little balloon notification that there was a problem and offering more help if I clicked on it. The “more detailed” help was just this:
Could not load file or assembly ‘Microsoft.Web.Diagnostics, Version=7.9.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35’ or one of its dependencies. The system cannot find the file specified.
Not really all that helpful.
So I started digging. I started adding diagnostics to the start of the IIS thread to see what it was doing. Then I ran that same command in a command prompt – aha! Much better!
C:\Users\Steve\work\client>iisexpress.exe /path:"C:\client\src\Web" /port:8089 Copied template config file 'C:\client\lib\IISExpress\AppServer\applicationhost.config' to 'C:\Users\Steve\AppData\Local\Temp\iisexpress\applicationhost201141420241120.config' Updated configuration file 'C:\Users\Steve\AppData\Local\Temp\iisexpress\applicationhost201141420241120.config' with given cmd line info.Starting IIS Express ... Failed to call HttpAddUrl with http://localhost:8089/ Failed to register URL "http://localhost:8089/" for site "Development Web Site" application "/". Error description: Theprocess cannot access the file because it is being used by another process. (0x80070020)Registration completed Failed to process sites Report ListenerChannel stopped due to failure; ProtocolId:http, ListenerChannelId:0HostableWebCore activation failed. Unable to start iisexpress. The process cannot access the file because it is being used by another process. For more information about the error, run iisexpress.exe with the tracing switch enabled (/trace:error).
So it isn’t completely clear from that either. The “cannot access the file because it is being used by another process” message is really referring to the port that IIS wants to listen on! That port number, 8089, was hard coded into my build script, and was taken by someone else! Rather than just pick a different port and move on, I wanted to see who it could be… the netstat command to the rescue. I used –b to show the name of the executable and –o to show the process ID.
C:\Users\Steve\work\client>netstat -b -o Active Connections Proto Local Address Foreign Address State PID TCP 127.0.0.1:1109 STEVEDONIE:19872 ESTABLISHED 4780 [Dropbox.exe] <snip>… [firefox.exe] TCP 127.0.0.1:8088 STEVEDONIE:8089 ESTABLISHED 8092 [googletalkplugin.exe] TCP 127.0.0.1:8088 STEVEDONIE:8108 ESTABLISHED 8092 [googletalkplugin.exe] TCP 127.0.0.1:8089 STEVEDONIE:8088 ESTABLISHED 7492 [firefox.exe] TCP 127.0.0.1:8108 STEVEDONIE:8088 ESTABLISHED 7492 [firefox.exe] <more snipped>…
Turns out it was the google talk plugin and firefox talking to each other on port 8088 and 8089. I think the google talk plugin is using a really bad port range – that is such a common range for developers to run alternate web servers on!
Now that the mystery is solved, how to fix it? I decided to pick a more obscure port to run IIS Express on. I ended up just choosing 18089.
Finally, I also updated the code that I am using to start IIS to do a couple of things better:
Long time no post
Yep, been a LONG time since I wrote. Gonna try and get back to it now.
Since I last wrote I have left the Java world and I am now back in the .NET development space. I’m working at Headspring with some awesome people, and after a few weeks on the job I’m starting to remember my .NET skills. Mostly I’ve been working with a client to do a lot of design work. More fun stuff in my next post.
Why a culture of quality matters
My company just recently started using ADP for processing our paychecks. So far, the core functions that ADP provides seem to work well, in that I do indeed get paid regularly. However, they have also provided us with access to their ‘web portal’ (beware of portals – they may lead to another world!) that allows me to do things like update my w-4, change my address, or download PDFs of paystubs. Recently we have also started using other ADP provided websites for other HR-related functions including recruiting and a very badly done company directory.
The developers on my team have had a great time pointing out just how bad the usability on these sites are, and mentioned it to our HR person. Our director of HR is a wonderful person, and is doing a fantastic job for us, by the way. She said that she could pass our concerns along to ADP, but that we should document some of the problems. That is where I got stuck. There were so many problems, I wasn’t sure where to start. This morning, I started.
The task at hand was to acknowledge that I had read a certain company policy. I got email from HR:
In order to meet ERISA requirements, all employees eligible for one of our plans (regardless of participation) must acknowledge receipt and understanding of the document – Plan Documents, Certificates of Coverage, Summary Plan Descriptions.
I realize this may not be the highlight of our day, but it is an extremely important step in keeping our plans compliant.
Here are the easy steps which should only take a couple of moments.
Log on to our intranet site at www.portal.adp.com
Click on to the Resources tab – In the first column under Company Policy – follow instructions to acknowledge.
Feel free to contact me with any questions or concerns regarding this document or logging on to the site.
Sounded easy enough. But it didn’t seem to be doing anything when I followed the instructions. Every time I clicked on the link, all I got was a PDF downloaded to my machine, and no indication that I had ‘acknowledged’ anything. So we called HR for help. Part of the problem is that the website is explicitly “Internet Explorer 6.0 or higher” only. I typically use Firefox. So I switched to IE. Still not figuring it out. After I finally got through the 4 step workflow, I decided it was time for some feedback.
Here is the email I sent back to HR.
As a general indication of the lack of quality in ADP websites, I found several bugs in the “acknowledge this policy document” workflow:
This is sorta why I haven’t provided any feedback to ADP yet. There are so many problems, and my gut tells me that the company does not have a culture of quality, and any feedback I provide will do little or nothing to affect the culture. It may help in a few small areas, but the real problem is the company culture that allows things like this to ship.
If anyone from ADP happens to read my blog, I would welcome comments on what the company culture is really like. I could be wrong.
Updated Release Burndown Spreadsheet Template
I mentioned this release burndown template in one of my earlier posts, but I have updated it quite a bit since then, so I am re-posting the link, along with some instructions.
Here are the instructions – which are also in the spreadsheet itself.
This spreadsheet was evolved over several years, and incorporates work by Stefan Niejnhuis and Henrik Kniberg. It has been optimized for the process followed by a specific team, and while it can be used as a starting point for your own work, it should probably be adapted to fit oyur particular needs. I will try to describe some of the assumptions made so that customizing it can be done intelligently.
Basic usage is to start by editing the Work Remaining sheet. Set cell A2 to set your starting date. It will automatically fill out the remaining dates. Note that my team uses one week iterations that start and end on a Tuesday. Cell A2 is therefore assumed to be a Monday. Next, switch to the Stories sheet and start filling in one row for each story. You have to manually fill in the Code#, which is a unique ID. I just use incrementing numbers. The Buttons for Code# and Importance sort the stories. I typically keep the stories sorted by importance, but when adding a new story I sort by code # so I can figure out what the next story number is. For each story, fill in Story name, size (T, S, M, L) which automatically fills in the points column based on the lookup on the lookups sheet. Fill in importance – these should be unique numbers, with the most important things having the highest numbers. Typically I start by using 100, 110, 120, etc. and going up, leaving gaps to make it easier to squeeze new items in between existing items. It is very important that items have unique importance numbers. Fill in the created date and perhaps comments. Stories that have code numbers but no estimates get highlighted in yellow. Stories that are estimated but not prioritized also get highlighted in yellow.
For your day to day work, you will start by deciding on an arbitrary number of points you think you can do in one iteration. Sort the spreadsheet by importance, and start filling in the iteration column with ‘1’ and watch the ‘points this iteration’ cell until you reach your limit. As the iteration progresses, mark stories complete by filling in the ‘date completed’ column and putting a ‘y’ in the ‘Completed’ column. If you decide to cut a story from this project, just put ‘cut’ in the completed column. If you want to postpone a story to some future release, you can put ‘future’ in the completed column. Each day after standup, update the work remaining page. Look at the numbers at the top right of the Stories page (Completed and remaining) and transcribe those to the correct row on the ‘work remaining’ sheet. Watch your graph grow automagically. One thing that I do is to use Excel’s built-in ‘publish automatically when saving’ functionality to publish the sheet and the graph to some location on my intranet.
For following iterations, you will end the iteration by seeing how many points you completed over the past iteration (see the “Work Remaining” page, “5 day moving average velocity” and multiply that by 5. Assuming your team has the same capacity as the previous week, that is how many points you can commit to for the next iteration.
On the Stories page, there are three buttons at the top left. The first is “Generate Index Cards”. Pressing this opens a dialog with a few options that should be self-explanatory. When you press the ‘generate index cards’ button in the dialog, a macro will start that deletes the old cards page, then copies relevant information from the stories page into a new cards page, using the CardTemplate page as a template. Printing these on 8 1/2 x 11 paper using the current template will give 2 cards per page. We just cut those in half and track the weekly iteration on a bulletin board. I’ll blog about that sometime – keep your eye on http://stevedonie.lostechies.com/
The other buttons on the stories page are “compact view” and “expanded view”. These are basically toggles between two different views. I use the compact view most often. When editing stories, I will switch to expanded view to make it a bit easier to type in the story notes and ‘how to demo’ sections.
Don’t get too obsessive about it – the burndown is not the project, it is just a tool.
Note that this spreadsheet is a release-focused (rather than iteration-focused) burndown that has been created for the style of project that we work on, and may not be the best thing for you or your company. This was developed using Excel 2003, but is known to also work with Excel 2007. Also note that it does have macros, and that it is not signed. It comes with no warranty, expressed or implied. Use at your own risk. Your mileage may vary. Batteries not included. Do not mock happy fun ball. Enjoy!
Houston Alt.NET conference
Just in case you haven’t heard, the Houston Alt.NET conference is coming up in 2 weeks – there is still time to register.
http://houston.altnetconf.com/home
Now, I am primarily a Java developer, but I attended the first Alt.NET conference in Austin a couple of years ago, and what was ‘sort of’ the 2nd Alt.NET conference in Austin (aka KaizenConf). Both were just awesome events. The people that show up to these sorts of events are all people who are passionate about the craft of software and who take the time out of their lives to be continuous learners. There should always be a balance between work and life – I believe very strongly in spending lots of time with my family. But if you possibly can, I highly recommend coming. You won’t be disappointed.
Looking for a new team member
<EDIT – this is long since filled, just in case you’re wondering.>
I have an immediate opening for a software developer.
Level of experience is not my primary criteria. I am more interested in
good object oriented design skills and a willingness and ability to
learn and work in a team environment.
About the company: Drillinginfo is a smallish company (about 100
people). We gather data on the
domestic oil and gas industry and put it all into a big database with a
web front end with search, maps, etc. We sell subscriptions to
companies ranging from 1-2 man shops all the way up to ExxonMobil. In
the past few years, we have been growing at an annual rate of 30-40%.
This year we expect that to be lower, but still growing. The company is
about 9 years old, is privately held (no venture capitalists telling us
what we should do this quarter), and has been profitable for several
years. We offer a comprehensive benefits package including a 401K with
match, company-assisted health insurance, vacation, etc. The company is headquartered in
Austin, TX, on the south side of town near Loop 360 and MoPac. We have
a great office space with views of downtown, direct access to the
Barton Creek greenbelt, an exercise room, covered parking, and free
lunch once a week.
About the team: I
lead up the data integration team that writes the loaders bringing new
data into the system. The team is 5 people, and we work in a large team
room. We believe very strongly in the principles described in the agile
manifesto, and use most of the XP technical practices along with Scrum
project management practices. The software is 99% Java, with some
groovy used
in a few select places. We use a lot of open source tools and believe
in contributing back to those projects where we can. The great thing
about working here are the smart people you’ll get to work with, the
camaraderie of the team and the company, and the technical challenges
we run into daily.
Refactoring project update #2
So, work on the refactoring project continues. We had a meeting with some of the key stakeholders, and came to an agreement between everyone that we should strive for several small releases. Our first release goal is fairly modest, and actually removes some little-used functionality in the system. We’re starting by setting up an end-to-end automated smoke test of the system. All of this is being automated using Hudson as our CI server. We approached the problem sort of like we would TDD, but in a larger context. Step one was to imagine what we wanted the end result to look like. Something like “Whenever a code change is checked in, we want to create a deployable packaged loader, save that artifact somewhere, then run a smoke test of that packaged artifact”. That led to us looking at the packaging and artifact repository system we had been using. We had been using a system very similar to what I described in a post at my old blog in which built artifacts were checked into subversion. There were some issues with that system, and we’ve been wanting to move more towards a maven style of managing dependencies and build artifacts, so we spent a day or so getting that set up. On a side note, maven can be a pain in the butt.
So following up on my previous post regarding Hudson and CCTray, we now have all good builds!
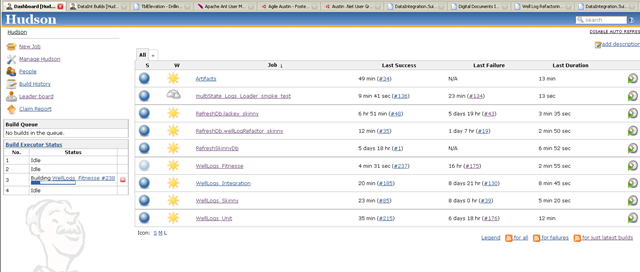
Our next step is to get some FitNesse tests around some of the data validation aspects of this loader. The current loader is a bit rigid about how it does things – it uses exceptions for flow control (blech!) and just dies completely if there is any problem with the incoming data. The folks who run the loader have found this ‘feature’ a bit annoying. They run the loader and after running for an hour or so, it will die because of one problem. One of the new features we are adding is the auditing system we have developed for our previous loader projects, so problems get recorded in a standard format, but the loader can continue on with its work, loading the items that are valid, and skipping those that are not. The audit report is then sent back to our data entry group so that they either add to or correct the incoming data. We’ll also set up some additional validations on the data entry side to catch the problems earlier.
CCTray with Hudson
Hurrah! Eric Anderson did some research this weekend and we now have our CCTray lights and speech working again!
Back when we were using CruiseControl.java for our builds, I submitted some patches to the CC.net project to allow the CCTray application to properly control X10 build status lights, and also to support text-to-speech for announcing build status changes. We really liked having that. We had a couple of lava lamps set up in the center of the team room to show the status of our builds – that allows us to see the status of the build when we come into the room. The speech (It says things like “The Well Logs Refactor project has started building” and “The Well Logs refactor project reports Yet another successful build”) helped us stay hyper-aware of the state of things. Having a periodic announcement that a build is starting reinforces the ‘pace’ of the team.
So, when we started using Hudson for our build server, we were disappointed that the rss format it shows didn’t work with Hudson. I looked around a bit, and while Hudson has its own ‘tray’ application, it didn’t do the stuff I wanted. I spent a little time looking at Hudson source code, thinking about writing a plugin to support the CC xml format. I looked at doing another patch for CCTray to support reading the Hudson RSS or XMl or Atom feeds. But I never got very far on those projects. Getting actual project work done was always a higher priority.
But now it is working again, and there was much rejoicing in the team room this morning. In order to spread the word that Hudson does output CCTray compatible xml, I am writing this post. The magic URL to enter into CCTray is http://hudsonserver:port/cc.xml and is described more fully on the Hudson Wiki.
Here is a picture of our newest build light setup:

Yes, the build is broken! We’re creating a new smoke test at the moment, and fighting with Maven configuration. We’re also going to neaten up the cords Real Soon Now.
Here are the three X10 modules on the wall. Pretty ugly. Might be a weekend project to mount the modules inside the light fixture, so we can just have a single cord coming out.

Finally, here is a pic of the team room – we have a long rectangular room, and mounted the lights on the short wall that is off the left edge of this photo.

Next thing for me will be a much simpler patch to CCTray to support three lights in X10. Currently it only supports ‘green’ and ‘red’. I want to make it so that the yellow light also comes on while a build is in progress. So the color scheme would be:
subscribe via RSS