Parsing a URL with a Regex
If that title didn’t strike you dead with fear, then you’ve never attempted this impossible task before. I consider it right up there with finding Shangri-la, Atlantis, Z, or El Dorado.
Lots of ink has been spilt bytes have been wasted seeking this mythical creature but no silver bullet has been found. Thanks to a Mike Strobel, a friend on twitter, he pointed me to John Gruber’s attempt at the problem. You may know John for his co-authoring of “markdown.” Needless to say, he knows a thing or two about parsing text.
John’s regex is nearly perfect and captures most of the nastiest test cases he or I could throw at it. He released this pattern as public domain. But it doesn’t appear to be actively maintained anywhere that I could see. Otherwise, my Goggling skills are failing me. If you know of such a project that is actively maintaining his pattern, please let me know in the combox below.
I wanted to get this thing on Github ASAP so that the world might begin maintaining this thing in the hopes of, together, developing the One, True, Perfect URL Regex Pattern (OTPURP – ok, so I need better marketing).
If you have interest in something like, or if you have developed the OTPURP and wish to share/contribute it to the world, please check out my attempt to centralize it:
https://github.com/chadmyers/UrlRegex
It if takes off, I’m happy to move the repo home to a neutral account and turn control over to someone or someones else.
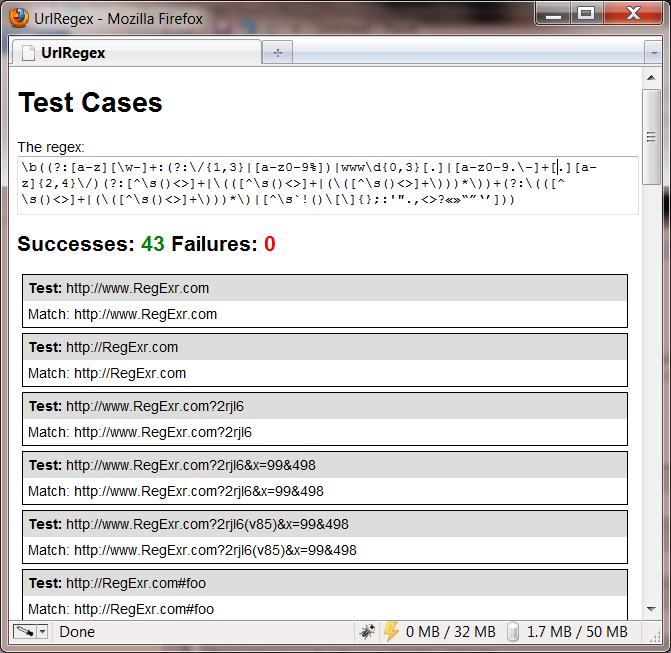
I’ve set up a test suite for it based on John’s test cases and some of my own. If you clone the source and open start.html, you should see something like this: