How We Do Things – The Team Room
This content comes solely from my experience, study, and a lot of trial and error (mostly error). I make no claims stating that which works for me will work for you. As with all things, your mileage may vary, and you will need to apply all knowledge through the filter of your context in order to strain out the good parts for you. Also, feel free to call BS on anything I say. I write this as much for me to learn as for you.
This is part 8 of the How We Do Things series.
Everyone should basically know what a team room is by now, so this post is going to just be a look into how we set ours up, how we got the team to buy in to the change from private cubicles, what we’ve noticed since creating the team room, and my thoughts on privacy and productivity.
When we first started growing our team, we were scattered about. A few of us had private offices, the rest were in cubicles with high walls. As we increased staff, I began to look at some alternatives to this situation. The space allocated to me was a rectangular room about 54’X18′ with an adjacent office that was about 15′ square. Not a lot to work with in a traditional cube setup, which is what I was asked to pursue. So I took this as an opportunity to build the team room I had been wanting.
What we came up with is “pods” of 3 desks each, with about 1′ mesh dividers above the desk surface. This gave everyone their own desk, and their own little area, but they were still together, and everyone could see and freely talk to everyone else.

Steve Harman once asked on twitter if private desks were anti-productive, and I answered that I didn’t think so when used appropriately. I know a lot of team rooms just do the flat table thing and everyone sits shoulder to shoulder at all times. That’s fine, I guess, and great for pairing, but people do need a place of their own. Someplace they can check email and their bank account without everyone looking over their shoulder. Someplace where they can put their knick-knacks. People like desk drawers to store things in. It’s psychology 101. People need a little space. At least the people on my team do.
One of the problems with some of the things we do in agile-type software is that we ignore the human factor, we ignore team dynamics and personalities, and try to make everyone the same. This is probably at least partly why a lot of teams push back on these practices, and why they end up falling down.
So we compromised, and people got private desks that were put together in such a way as to not hinder the “team” aspect of the team room. And I think it’s worked well.
We outfitted the team room with plenty of whiteboard action:

It’s important to have a lot of areas where people can collaborate and try out ideas. In addition to the team room we also have a “conference room” for just us that is separate, has a whiteboard and a nice projector, where people can gather and do design and planning sessions.
Since the desks aren’t really conducive to long-term pair programming, we set up a pairing station at the end of the team room, and we turned the extra office into what we call “pairing jail”. Pairing jail has two pairing stations and another whiteboard, plus all the equipment we need to test our hardware integrations (microscope, camera, barcode scanners, etc).

Each pairing station has a 24″ monitor, extra keyboards and mice, and is a nice flat surface people can work on.
This is the compromise between pair programming and private desks. We pair most features, and most of the developers are pairing about 5-6 hours a day. However, we have an uneven number of developers, and sometimes people are working on something on their own, or spiking something, or just doing whatever else, and having a semi-private space keeps morale up.
We have 7 developers so 3 pairing stations works. When we add more staff, we add more pairing stations. Pretty simple.
We also work on a few different projects simultaneously, which makes the separated pairing room nice. That room usually becomes the war room for the two pairs working on the biggest thing, so they can have all their conversations and whiteboard sessions without interfering with the conversations of the third pair who is working on something totally different. It works for us.
People seem to organize themselves fairly well into various areas, they respect the whiteboards when there’s real work on them (people outside the team don’t always respect the whiteboard, which can get annoying, but that’s another story)
At first there was resistance to the team room concept, and I’m sure a lot of people come up against this. To overcome the objections I did the simplest thing that could possibly work: I gave up my office and sat in the team room. When the boss gives up his office, people are less likely to complain about sharing space. Then they get used to it. Then, over time, they see the value, and the organic process of gelling a team happens.
There was also resistance externally to the idea at first (and still some today, a couple of years later). Other managers at my level didn’t understand why I left my office for a desk in this room, and I took a lot of not-so-subtle teasing for it. People didn’t understand the collaborative nature of a team room, because corporate America is used to peons in cubes, managers in offices, and communication via email and scheduled meetings. This is just something people have to get over or not. I stopped caring. The results spoke for themselves. Don’t let the sheep drag you down.
The team room isn’t just for developers. I sat in there until very recently (gave up my space for expansion since I’m moving soon anyway). The business analysts are in the team room. The QA guys are in the team room. Everyone is together, and everyone talks, and everyone is accessible.
Not everyone has the perfect big room for a team room, I didn’t. You have to find a way to work with the space you have, be creative. The most important thing is getting the team together, in the same place, and removing the barriers.
A team isn’t built overnight. It takes time. When people aren’t used to a team environment, a collaborative environment, you can’t just throw them together at desks and expect magic. It’s a process. I will say that since we put the team room in place, after the first month or so, it’s been amazing. People communicate. They talk. They whiteboard. They get together at each others’ desks for impromptu design sessions. They pair on things they weren’t even planning to pair on. They collaborate. Without the team room in place we would not be where we are today with either our process or our practices.
Technorati Tags:
how we do it, improvement, lean, management, quality, software, team, planning
How We Do Things – Specification (Using the right tools)
This content comes solely from my experience, study, and a lot of trial and error (mostly error). I make no claims stating that which works for me will work for you. As with all things, your mileage may vary, and you will need to apply all knowledge through the filter of your context in order to strain out the good parts for you. Also, feel free to call BS on anything I say. I write this as much for me to learn as for you.
This is part 7 of the How We Do Things series.
This post was co-written with Cat Schwamm, business analyst extraordinaire.
In the last post we talked about how we approach specification philosophically, as an iterative, JIT process. In this post we will take a look at the tools we use to create specifications.
User Stories and Text
User stories and other text documents are the bread and butter of defining work, and we use them like crazy. Our story practice has evolved over time, and we have come to a place where we feel that, when used appropriately, our stories are very effective. For a deeper look at the guidelines we use to construct stories, I recommend you go check out Cat’s post on the subject. Go ahead. I’ll wait.
Okay, welcome back. Here’s the thing, stories and tasks are only part of the equation. Stories alone aren’t enough to define a system, and trying to define everything in text is a fool’s task. (I’ve been that fool). You need a full arsenal of specification tools to do the best job possible.
Story Pros: captures textual data well, tells the story
Story Cons: not everything is meant to be captured in text
Mockups
Mockups are a very useful tool when specifying details of how things should work. With stories, you really can’t add a lot of design and implementation details or the signal to noise ratio becomes too high and shit gets overlooked. A basic rule of thumb we employ on the team is “things that don’t get communicated well in text shouldn’t be forced into a text medium.” Basically, if you’re going to try to describe the way something should look in a story, a) it’s probably not going to look the way you actually picture it b) that story is now noisy as crap and people are going to ignore more important parts. With a mockup, you don’t have to take forever to do a flashy, literal, perfect screenshot in Fireworks or anything; you can just drag and drop Balsamiq controls around and voila. Ya got an aesthetically pleasing mockup that humans go nuts over. In five minutes I can mock something up in front of a developer, explain how it works, and they are ready to go.
Another great thing about mockups is that they are extremely useful for getting user feedback on specs without distracting the user that “this is the final product, no more input.” You can use a mockup to discuss workflow and layout without getting mired in fine-grained detail. The last time I was at the lab, I went back to my hotel room for a couple of hours and mocked up apps for 4 workspaces, brought them back to the supervisors and was able to get plenty of good feedback and make edits right there in front of them. Gold.
Mockup Pros: Time-saver, gives the gist of what you want, keeps your stories clean while still conveying what you want, good to show to users.
Mockup Cons: Can fall into the trap of putting everything on a mockup just like you would put everything into a story and it’s inappropriate
High Fidelity Design
How easy is it to develop from what basically amounts to a screenshot? You know exactly how everything should look, you can strip images out, you don’t really have to think about it.
Wait a minute. There’s a red flag.
You don’t have to think about it? That’s a paddlin’. A high fidelity screenshot, while beautiful and easy to work from, gives developers a signal that this screen is a specification set in stone. They see what it needs to look like, they build it like that. It’s just like BDUF; the high level of detail and granularity means that people won’t think about what they’re actually building, they’ll just duplicate what they are given.
Screenshot Pros: Hotness, high level of detail, easy to work from
Screenshot Cons: Removes developer thought, can take a long time to create such a design
Conversation and Whiteboarding
While each of these mediums has plenty of merit and many benefits, conversation and whiteboarding are my (Cat’s..well, OK mine too) favorite method of specifying work. There is nothing like having the team (or pertinent members) together, talking through the workflow of a feature/app, mapping out how everything works, doodling out a rough idea of what things are going to look like and how things will come together. It is so damned valuable to have the working group together, talking through how things are going to work and getting their input. While business analysts and managers can come together to specify the general nature of how things need to work, having different members of the team around will help to eke out edge cases or problems that may not have been thought of in original discussion.
Conversation is obviously important by itself too; user stories are written to leave plenty of room for conversation. If you lose communication on your team and people just go off to code in the dark, a lot of the intent and original specification is lost.
Whiteboard Pros: Mapping workflow, multiple sources of input, easy to sketch out an idea/easy to change an idea, whiteboarding is fun as shit, conversation fully fleshes out ideas
Whiteboard Cons: Easy to get lost if not captured appropriately
While we’ve clearly chosen a favorite medium, you really can’t use just one. Each medium has a lot to offer depending on the scenario you are working with, and just like any other thing, you have to use what works naturally for the team in context with what you are doing.
Technorati Tags:
how we do it, improvement, lean, management, quality, software, team, planning
How We Do Things – Evolving our Specification Practice
This content comes solely from my experience, study, and a lot of trial and error (mostly error). I make no claims stating that which works for me will work for you. As with all things, your mileage may vary, and you will need to apply all knowledge through the filter of your context in order to strain out the good parts for you. Also, feel free to call BS on anything I say. I write this as much for me to learn as for you.
This is part 6 of the How We Do Things series.
This post was co-written on Google Wave with my colleague Cat Schwamm, who keeps me sane every day.
In this part we will explore how specification practice has evolved in our team, from a very waterfallish BDUF approach to what currently is a very lean approach to specification. In the next part of the series we will talk stories and mockups and other tools we employ to make the magic happen.
Where we came from
We began our large LIS project in late 2004, starting with about 6 full months of writing specifications and designing the database. We created reams of documentation for each application complete with use cases that we knew we wouldn’t even implement until after the first version was released (sidebar: some of those still haven’t been done). We defined more than 100 tables of heavily normalized database schema. Before one line of code was written, we had spent six months of project budget.
As development continued on the project we found ourselves diverging from the specifications that had been created. The documents became little more than a roadmap, with the bold headers on functional groups and the basic usage stories becoming the guidelines that we followed. Much of the detailed specification and database schema went out the window as the system took shape and people began to see and give feedback on what was being produced. Too much specification gave us a false sense of “doing it right” and led us down many wrong paths. Balancingrework with completing planned features became a costly chore.
By the time the project was complete, it was clear that much of that up-front work had been wasted time and money. Had we top-lined the major milestones of such a large project, detailed a small set of functionality, and started developing iteratively, the system would have taken form much sooner, allowing for a tighter feedback loop and much less overall waste.
How we do it now – Overview
Lessons learned, we set about improving how we do specification. I already talked a little about this in the posts on planning, so please review those if you haven’t seen them yet. [part 1] [part 2]
When planning a new project of any size, we take an iterative approach. We start at a very high level, and strive to understand the goals of the project. What need does it serve? Who will be using it? Are we competing with something else for market share? Is there a strategic timeline? What’s the corporate vision here? What are the bullet points? We will fill in details later. We only want broad targets to guide us further.
When we get closer to development, we start to identify smaller chunks of functionality within each of those broad areas. This is still pretty high level, but done by business analysts and management on the IT team. We start to identify MMFs (minimal marketable features) and group them up in order of importance to help determine next steps.
MMFs in hand, we take the first one and start defining it further. This is where the information from the planning post comes in. We start to write stories (Cat has a great post detailing how to build effective stories). The other information gathered to this point sits dormant, with as little specification work done as possible, until such time as we are getting closer to working on it.
Over time, and only as needed, we put more and more specification on the system, and this is done in parallel with development. In fact, often the most specific information can only surface during development of those features, as they take shape, and as we understand how users will react. Specification should be every bit as iterative as coding.
Reduced to its essence, we JIT specification at many levels to allow maximum flexibility to change direction with minimal wasted work.
Gemba is an essential part of specification
It’s often the case that a team relies on “domain experts” to provide them with the specifications they need to build software. This is the BDUF way – gather in committee and have the all-knowing user tell you what to build. Fail.
Cat sez:
The dev team works out of the corporate office in Florida, while the actual laboratory is located in upstate New York. As a result, it is often an exercise of the imagination to figure out the best way to create things for them. Before I visited the lab, I relied on information from others, emails back and forth to the lab crews working all weird hours of the night, and my knowledge of the applications currently in existence. I really only ever got half the picture, and it was difficult to ensure that the things I was specifying would fit into the lab users workflow well without actually knowing what was going on up there. When I visited the lab my whole world was changed. Actually seeing how users interacted with the software and seeing ways they would work around what we didn’t have (open Excel or Word documents on their desktop, a wall covered in post-it notes). Just from walking around talking to people for 2 days, I probably got 50 requests. And they never would have asked for them; they would have just kept suffering. Being there showed me everything about how they worked and a million ways I could improve their lives. The experience was invaluable to both me and them, and each subsequent trip has just improved my knowledge of the way we work and the way they interact with our software.
There is no substitute for a certain amount of domain expertise being resident in the team room. Your domain experts are experts only in their domain. They may know the workings of a histology laboratory inside and out, but if you ask them to design a system to support that lab, they’ll come back with something that looks an awful lot like excel and post-it notes.

Yes…this is a workaround someone had for something our system didn’t do. It’s been fixed 😉
Lean has a concept of the gemba attitude and genchi genbutsu, essentially, being in the place where the action happens. Developers and business analysts have to work with the domain experts, in the place where the work happens, and observe the true workflows in place before hoping to design a system to support them. You cannot get this information from sit down meetings and emails with domain experts. You must go and see for yourself, or you will miss things.
In the next post we will talk specifically about the tools and techniques we use to specify work, and how we combine them to form complete pictures of a system (spoiler alert: it ain’t just stories).</div>
Technorati Tags:
how we do it, improvement, lean, management, quality, software, team, planning
Going Away Geek Beers
Most of you have heard by now that I am leaving Florida for the concrete pastures of New York City.
I’d like to have a get-together of some of the Florida community guys (and gals) Monday, Nov 16, in Ocala at 7pm until we decide to leave.
It’s truly been a pleasure working with this community over the last few years, and I will miss you guys. So..come on out and buy me a beer! 😉
Location: O’Malley’s Alley
My phone is 352.209.0943 drop me a line if you get lost of want to confirm you’re coming. So far looks like a real good group will be there, including Cory Foy, Sean Chambers, Scott Densmore, and Will Green, the amazing Cat Schwamm as well as members of my team. Hope to see you Monday!
Hang in there baby birds, I’ll feed you
Quick housekeeping note – How We Do Things series is not cancelled, I haven’t given up on it or run out of steam, it will still press forward.
Trying to get a lot wrapped up both at home and at work in preparation for my move to New York, so I lapsed a bit, but I will be back on it soon.
My Favorite System Deploy Story
I just remembered this and regaled the newer members of the team with this amazing story that happened when we rolled out our new enterprise lab management system a few years ago.
The end result of all of our processes basically is a pretty report that goes to our client doctors and gives a diagnosis.
We were up in New York for a month of 20 hour days getting the system finalized and deployed. It was a wholesale changeover from old system to new.
Literally the day before deployment day I was up all night creating the reporting engine and finalizing report layout. Everything was happening under great pressure.
We rolled the system out the next morning, and things seemed to be going smoothly, until a client called us frantically claiming that there was a picture of a MONKEY on their report they just received.
This put us into panic mode. What did we do wrong? Did some bogus image from test make it into production? Did I do something incredibly strange when I was creating these reports on no sleep? What went wrong?
We immediately dropped everything and started searching databases and code to see what could have happened. This was basically the first report generated by the new system, and somehow it had a MONKEY on it!
After unsuccessfully trying to find the phantom monkey in the system, we asked the client to fax us a copy of the report. We waited with bated breath, the whole team huddled around the fax machine.
After a few minutes, paper started to come out…
I snatched it from the machine…
There was indeed a monkey. The page also said “HP LaserJet Printer Test Page”.
Sigh.
How We Do Things – Testing Part 2
This content comes solely from my experience, study, and a lot of trial and error (mostly error). I make no claims stating that which works for me will work for you. As with all things, your mileage may vary, and you will need to apply all knowledge through the filter of your context in order to strain out the good parts for you. Also, feel free to call BS on anything I say. I write this as much for me to learn as for you.
This is part 5 of the How We Do Things series.
In the last installment I talked about our the evolution of our TDD/BDD Practice. In this one, I will talk more specifically about the tools we use, where we apply TDD, and other testing practices we employ.
n.b. I’ll use “specification” interchangeably with “test” here, so when you see it, don’t think “spec document”.
.Net Testing
In our .net applications we employ TDD/BDD with a combination of NUnit, TestDriven.net, ReSharper, and a sprinkling of extension methods and abstract base classes inspired by Scott Bellware’s SpecUnit.net project (now defunct, if you are looking for a more full context/specification framework, check out the excellent Machine.Specifications (MSpec) from Aaron Jensen).
Our standard abstract base class for a specification looks a bit like this:
[TestFixture]
public abstract class SpecificationBase
{
protected virtual void Because(){}
protected abstract void Before_All();
protected virtual void After_All(){}
[TestFixtureSetUp]
public void context_before_all_specs()
{
Before_All();
Because();
}
[TestFixtureTearDown]
public void teardown_after_all_specs()
{
After_All();
}
}
That’s it, pretty simplistic. With this base we try to “encourage” context to get set up in [TestFixtureSetup] rather than [SetUp], the idea being that if a context is going to fit a whole specification (testfixture) then it’s more efficient to set up once. We don’t provide a base for [SetUp] and [TearDown] because we want to see those ugly tags in our specification class to remind us to question if we really are breaking up our context appropriately.
We also make heavy use of extension methods to wrap assertions, so that we can do things like
observedState.ShouldBeTrue();
</p>
As for the test runner, the R# test runner is great, and pretty, and we will fall back to that to get a nice output list of specs at the end of implementing something, but for the sake of speed and flow, while we’re actually implementing we tend to prefer the TD.Net runner. This isn’t mandated though, and some guys stick to the R# runner for everything.
Higher up the stack in .Net
As it stands today, we do not do any web development in .net. We only have WinForms and a smattering of WPF.
We don’t use a FIT tool, or a scenario tool like NGourd, because we haven’t really felt a need for this. We do intend to examine StoryTeller and see if it adds value to our process, and when we do, I’ll write about it.
We’ve found that using separated presentation patterns (such as Model-View-Presenter) allows us to very easily drive out everything but the actual UI forms with NUnit and context/specification.
For UI test automation in .net we use Project White. We do this similar to how you would run Selenium or Watin tests, carving out chunks of functionality to test as a unit and automating it. Usually these test units are organized around a given MMF because it feels like a natural fit.
We do not have anywhere near 100% coverage for automated UI testing at present because the cost to do so immediately can’t be justified, so we move forward putting new things under test in this fashion and backfill as we have time. It took us a long time to find a tool we could use (note I didn’t say “that we were happy with”) and Project White fits the bill well enough, but, simply, there’s just a lot of things you can do in a WinForms UI that makes it extremely difficult to test in an automated fashion.
TDD/BDD in Ruby and Rails
In our new and still evolving rails practice, we utilize Selenium and RSpec for TDD and for higher-level automation tests. We do context/specification style BDD for our models, and typically do not test-drive our controllers at that level. We will drop down and put some unit tests around our controllers when we feel like we have a hole, or something complicated, but we usually take that as a sign to either move functionality to a model or simplify design.
We started using Cucumber for scenario tests, but were not happy with the workflow. The tool itself is great, but the workflow didn’t get us where we wanted to go. We felt like we were repeating motion on a lot of specification between Cucumber scenarios and RSPec-driven model specs, and that was wasteful.
Instead of that, we test-drive scenarios in RSPec by automating Selenium. This is what covers our controllers and views and sets the expectations of the feature. We do this in context/spec style as well, and the specs (tests) are created as part of the story exploration process, ahead of code being written.
Manual QA and “Acceptance” Testing
We do have a manual QA process, and I’m not sure that you can safely get away from that in a non-trivial system.
The trick is to make it so that the manual exploratory testing is strictly exploratory, and that by the time a feature gets to this stage TDD and higher-level automated tests are covering the correctness of the expected execution paths.
We combine manual exploratory testing with manual acceptance testing, and the idea here is that any work coming back should be in the realm of usability concerns and slight functional tweaks, not actual bugs. I feel like we’ve hit a pretty sweet stride here actually, and the ratio of bugs found at this stage to usability issues found at this stage is about 1 to 10. This is a good thing. This means that we have done our due diligence ahead of time with automated tests and our manual testing is concerned with what manual testing should be concerned with – usability – 90% of the time.
Tests as Documentation
We never have had a reason to show test output in any form to a user or other business person, so we haven’t invested a lot of time into getting nice runner output formatted anywhere (and that’s also why cucumber and FIT don’t really have much of a value proposition for us). Our tests themselves are constructed so that both the testers and business analysts can read them and understand the specifications, and the testers, business analysts, and developers all collaborate ahead of time to actually scaffold out the specifications.
By involving the full team in creating the specifications we ensure that they have value beyond the developer desk, and that we are reinforcing among all parties the expectations about the system. This is all about communication, and it’s the key to any agile or lean development process.
When we *don’t* TDD
We do not practice TDD 100% of the time. There. I said it.
We don’t typically TDD spikes. Rather, we don’t mandate it. If you want to TDD a spike go for it. Sometimes I do, sometimes I don’t. Depends on the context.
I already said we don’t TDD our rails controllers or views, and we don’t TDD the actual forms of our WinForms apps. This is a choice where we figure the cost/benefit ratio is not there. YMMV.
There are certain areas of our system that don’t end up getting TDD treatment when we add to them. This happens for various reasons, part of which is that it’s just hard to TDD them, and part of which is that it doesn’t add much value anyway. One such scenario is in places where we export our data into a common xml format for integrations with other healthcare systems. In these scenarios, the code to generate the xml was done with TDD, and the format is standard. The actual generating and manipulating of the data to feed to the xml builder involves a lot of copy/paste functionality and one-off tweaking on a line-by-line basis. This is all kept black-box to the system at large, uses a known (and tested) api to grab the data, and just doesn’t make sense to TDD. There’s a lot of copy/paste because the exporters operate independently and need to have 90% of the same functionality across the board but with variability in how the data is modeled. It works, even though it sounds like it could be constructed better on the surface. You’ll just have to trust me.
We also don’t TDD our reports. Much like forms, there’s too much tweaking and fiddling to get them to lay out right, and TDD just doesn’t work for us there. But as in the previous example, the api’s from which the reports get their data have been driven out by tests.
Technorati Tags:
how we do it, improvement, lean, management, quality, software, team, planning
How We Do Things – Evolving our TDD/BDD Practice
This content comes solely from my experience, study, and a lot of trial and error (mostly error). I make no claims stating that which works for me will work for you. As with all things, your mileage may vary, and you will need to apply all knowledge through the filter of your context in order to strain out the good parts for you. Also, feel free to call BS on anything I say. I write this as much for me to learn as for you.
This is part 4 of the How We Do Things series.
Today we’re going to talk about how we evolved our TDD practice, the troubles we faced along the way, and where we stand now.
I already mentioned that when we started this project oh so many years ago we did not construct it with TDD, and I’ve mentioned how well (from the user perspective anyway) it turned out. So, let’s dispel any notions that I’ve ever said that no software can be successful that wasn’t built with TDD, because the flagship of my career was.
However, I will qualify that by saying that now, when the team has to go into that old code to modify it, we curse ourselves constantly for not having done TDD. I can say with confidence that had the system been designed with TDD as we practice it now that changes would be easier to make, and the code would be easier to understand 5 years later.
But practices evolve, and that’s what this series is about, non?
Many False Starts

Now we started with every intention of doing TDD. We made an effort, but it fell by the wayside very quickly as pressures mounted. At the time I had only a very surface understanding of TDD and had not been a full-time practitioner at any point. The other programmer on the team at the time was a fresh out of high school kid with very little experience. We weren’t pair programming, and I lacked the knowledge and experience to mentor the TDD practice, so it was essentially a non-starter.
For a while we did do unit and integration testing in test-after (TAD) form, but that fell apart as well. We fell into the trap of optimizing the “code complete” workflow at the expense of test coverage.
As time went on my understanding of TDD grew. I got more involved in the community and started practicing more on my own. I credit Scott Bellware, Dave Laribee, Ray Lewallen, and Jeremy Miller primarily for either directly or indirectly influencing and increasing my knowledge of the practice.
When adopting any advanced practice it is incredibly important to have masters to learn from. This is true in programming and elsewhere. These guys, whether via their blogs, or conversations, or actually sharing code helped me immensely in bootstrapping my testing practice.
As a team leader, it’s also important that you have the tools to mentor your team in a new practice. My folly the first few times we started (and quickly stopped) doing TDD was not being able to do that mentoring, but trying anyway. It broke down quickly.
Eventually we started picking up TDD again. It wasn’t a 100% thing, but we were making the effort, and I was doing a much better job leading the way. I was actually working with my team to help them write tests rather than simply giving the directive and some links to read. I was educating them on OO principles that would help them understand how tests can drive design, rather than letting them flounder.
This is all not to say that I did everything perfectly, in fact rather the opposite. I didn’t understand how many disciplines were at play for successful TDD adoption at first, and I take full blame for not having the leadership ability to get them there sooner.
We went along like this doing TDD, though at times very fragile and naïve TDD, on new development where it was easy. It wasn’t until after Scott introduced me to Context/Specification (c/s) at one of the early alt.net events that everything seemed to click. I came back from that event and gathered my team, which had grown to 3, in a room where we pair programmed as a group for several days and explored c/s and BDD together. By the end of that week it was as if a light went on for us collectively, and our testing practice from that point on was much more robust.
As new members joined the team we immediately went into mentoring on c/s. At the time we weren’t pair programming as a rule yet though, so it was difficult. We also were still dealing with a significant legacy code problem and putting tests around new things to interact with old things that weren’t all that testable was difficult to say the least.
Frustration finally set in for us and we set about making our legacy codebase more testable. We didn’t have time or budget to do this all in one fell swoop, so we did what any good team does…refactored as we went. Slowly but surely we started getting comfortable with a few patterns that we could employ to refactor our legacy code for tests while adding new features or fixing bugs, and our TDD practice really started to get teeth.
The Catalyst – Pair Programming

When we finally introduced pair programming as a regular practice (more on this in a later post) we started to see a real uptick in the understanding and appropriate application of TDD and c/s. Mentoring by the more experienced team members was happening in real-time, as code was being written, and understanding skyrocketed. There were other benefits to pairing as well, but again, that’s a later post in the series.
Suffice it to say, if I had to do it over again we would have introduced pair programming far earlier, and our testing practice wouldn’t have suffered from so many false starts for so long.
a_monkey_wrench
We were sailing along pretty well with our TDD and c/s practice in our c# WinForms applications, which was the bulk of what we did. Then we had some shifts in corporate priorities that saw us doing a lot more web work. Rather than go with the .net platform, we chose Ruby on Rails for this. We’ll talk about how we choose tech in a later part of this series as well.
The thing with going RoR was that it was totally new for us on a lot of levels. We hadn’t done any significant web-based work in years. I hadn’t touched the web since 2001 myself. Plus we were a total .net shop up until that point, and this was a completely new language, on a completely new platform. We had to learn ruby, rails, ajax, apache, linux, and a whole slew of related technologies.
It turned out that trying to throw RSpec and TDD into the mix was just too much for us, and we were at near zero productivity. We were under pressure to produce this first project, and prove that Rails was going to be a viable option for us going forward, so I made the call to suspend TDD for this project.
Some of you may call this a weak decision, and I totally get that. However, I had to make a choice, and the choice was very difficult. At the end, I chose to suspend a practice that we believe strongly in to get some velocity on learning all this new stuff and producing code.
By the end of the project, we were feeling the pain of a no-test environment. We got through it, and once again we definitely produced some working, amazing (to the user) software. But the combination of not being experienced with ruby and rails and not having tests took its toll toward the end as we found ourselves struggling to maintain and add to what we had done.
Asking for help
After the successful completion of the pilot project, we knew we would be moving forward with rails for a major web project that would have a big impact on the business.
We also knew we didn’t want to move forward with this major project without having our BFF TDD at our side, so we needed help to bootstrap the practice in ruby and rails to match what we did in c# and .net.
We started going down the road of learning RSpec and using Cucumber for acceptance testing, but the workflow felt foreign to us, and we weren’t able to find a rhythm that we liked.
We called Scott Bellware and brought him down to give a day of intense training for the full team in context/specification for rails with RSpec and Selenium.
Scott came in and gave us a great day of training and helped us solidify our practices in web testing and TDD for ruby and rails. By the end of the day we were all exhausted, but we had a great start down what we felt was the right path (I owe you a guest post on this too Scott, I haven’t forgotten).
Now this new project is moving forward rapidly, with TDD happening. The spot we’ve found that we like (for now) is that we do c/s in rspec for models, but don’t really TDD our controllers. The controllers get tested by the higher level selenium-driven scenario tests, and if they’re being constructed right, they should just be middlemanning things between the view and the model. We write the selenium scenarios in c/s style ahead of time to drive out what’s expected to happen, so for us, this practice appears to be working fairly well. I think we will be revisiting it however, in the spirit of continuous improvement, as we come up against places where we have holes in the practice.
Wrapping it up
So, the TLDR version: we didn’t always do TDD, and we had a lot of false starts along the way. I learned that it takes a lot of hands-on leadership to get it rolling, not just directive. If I had to do it over again, pairing practice would have been in place first, because it would have made it a TON easier. I also would have made sure that I was more in a place with my personal knowledge and experience of the practice before foisting it upon my team.
The practice has evolved massively over the last 4 or 5 years, and it has not been easy. But it has been worth it. This is anecdotal. I have no real numbers for you. But I do know that the pulse of my team is that life is better with TDD than without, and in the case where someone goes off on their own and does something without it, they usually come back when they have to maintain or extend it and say “man, I wish I had done TDD here”. To me, that’s proof enough.
Technorati Tags:
how we do it, improvement, lean, management, quality, software, team, planning, tdd, bdd, testing
How We Do Things – Planning Part 2
This content comes solely from my experience, study, and a lot of trial and error (mostly error). I make no claims stating that which works for me will work for you. As with all things, your mileage may vary, and you will need to apply all knowledge through the filter of your context in order to strain out the good parts for you. Also, feel free to call BS on anything I say. I write this as much for me to learn as for you.
This is part 3 of the How We Do Things series.
In the last post I talked about the various evolutions of planning the team has been through over the last few years. This post is about what we do now. Take a moment to read the last one to catch up on what the picture below is about.
The Planning Space-Time Continuum
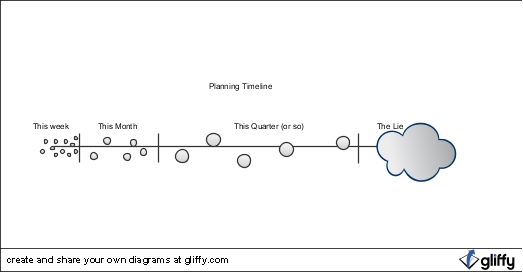
The basic gist here is that as items move from right to left they become more well-known, more defined, and more likely to actually be worked on.
JIT Planning Next Work To Be Done
We’ve come to a point where we plan, basically, as much work as we need to plan to keep work in progress until the next time we want to plan. I’ll try to make that a little less esoteric.
We intend to plan a week’s worth of work at a time, give or take. The acceptable threshold is typically anywhere between 3 days and 8. Usually this takes the form of planning just one or two minimal marketable features (MMFs – more on these in another post) depending on size. There’s a lot of “feel” to this, and that feel stems from having established a pretty rhythmic workflow and from having same(ish)-sized stories (more on that in another post as well).
Mechanically, the planning meeting looks like this: representative team members (usually myself, one or more BAs, the developers that will work on the MMFs, and a QA person) will get together and go through the stories that need to get worked on next. We’ll do a story workshop of sorts where we flesh out details of acceptance criteria, surface any issues or further questions, actually plan out some tests, and determine if the stories are appropriately sized.
If any questions or blocking issues come up at this time we will deal with them then and there by either talking them out, or if necessary tracking down the right people to answer the questions. If we can’t get the answers right away we figure out if we can get started without them and trust that someone will have the answer by the time we get to that point. This will spin up a thread for a BA or myself to go track someone down in the lab or elsewhere in the organization, set up a meeting, and do that whole thing.
This planning is unscheduled and happens as needed. If we are running low on work today, we’ll schedule a planning meeting for tomorrow morning. They usually last no more than 30 minutes unless there’s a lot of design discussion to be had.
Near-Term Planning – The Rolling Wave

The planning in the prior section is directly seeded by the planning done in this section. This is the next segment of the continuum to the right, and represents the picture of what we will probably be working on sometime in the next month.
This stage of planning doesn’t directly involve any developers or testers unless specific questions arise. At this point the BAs and I are sketching out the stories at a higher, not quite as detailed level, and stitching them together to form MMFs. We are figuring out what questions need to be asked and where these MMFs will fall in the slightly larger picture. Here is where we are evaluating priorities of features and roughly determining when they will be started. In short, we have about a month’s worth of stories, give or take, in states somewhere between fine and coarse-grained detail, with priorities, and we’re fairly confident that we will get to them in the next month. This is what a scrum team might call their product backlog.
This planning happens on a schedule every Monday morning. We go through requests, evaluate them, evaluate work in progress, and determine which stories to add finer detail to and queue up for the next work planning session.
This is a variation of Rolling Wave planning in that we don’t necessarily keep the “wave” the same size at all times, and we don’t make detailed work plans for the items in the wave. There’s also no guarantee that items move linearly from the end of the wave toward the beginning as time passes, since we allow for priority shifts within this space. In some ways, it’s more like a rolling cloud than a rolling wave, but I don’t know if I’m qualified to make up a new project management term.
Some weeks, like this week, we may not bring any new stories into the wave at all. We may sit down, go through the backlog, look at work in progress, evaluate current conditions, and determine that we don’t need to spend any time adding more work to the wave. To me, this is perfectly acceptable in the spirit of eliminating waste. We aren’t adding more inventory when we don’t need it, and we aren’t wasting motion defining things when there’s no immediate requirement. Sometimes our wave can get as lean as to only have a week or two in it, and sometimes it can bloat up to 6 to 8 weeks. We use this wave as our buffer to adapt to changing conditions.
There’s a real chance that the work put into the wave last week will be superseded in priority by new work identified this week. We don’t push that other work out just because the priority changed, we just insert the higher priority stuff where it belongs. This accounts for the occasional bloating of the wave, and we compensate by not adding to it next time.
Sometimes there is no priority work to be brought into the wave, or no stories that we can get enough information on yet, so we just let it go for that week and let it shrink in size. If you’ll pardon the metaphor, we let the size of this backlog ebb and flow fluidly.
The picture of the wave at any given time allows us to make decisions about what work will be delayed if new priority work is identified, and we can share that easily with project stakeholders. Because we know that we’re talking about a month or so of work, we are able to make statements about timelines of work that has been specified in enough detail and given enough priority to be in the wave. This makes external parties much happier.
The Roadmap
The sections farthest to the right are our next quarter/next year roadmap. This is where we would understand longer-running strategic initiatives or targets that we will ideally get to if, and only if, current conditions remain the same. This includes items from both the corporate initiatives roadmap, and our internal project roadmap. This could be anything from “In Q4 we are likely going to introduce a new product line” to “we’d really like to replace our hand-rolled data access with NHibernate.” We put this stuff on the roadmap to serve as the mile markers for where we (the organization, not just the developers) want to take our software. </div>
Some items on the roadmap will very likely get implemented, and we may know it well in advance, but their priority or maybe external dependencies aren’t such that we could reliably be planning this work yet, so it goes out here to the right for the time being.
Some of the items on the roadmap could very well never get implemented. These aren’t just the “man it would be great if…” items, though those are on there. They are also the items that are totally valid, have strategic value, but somehow never seem to win the priority battle with other items. These are the items that usually end up becoming factors in the decision to increase staff or potentially purchase something.
Or maybe they are items that get totally replaced by something better. As an example, we had a project out here in this space for almost two years. Everyone wanted to do it. The business was hyped on it. They kept asking when we could get to it, and kept insisting it was going to be a key part of our service offerings. However, it never could beat out other priorities. In two years it never once won a priority battle. Recently we uncovered a vendor that would provide us with a 90% solution that would take mere weeks to integrate, versus what was looking like a multi-month project. The original target came off the list, replaced by the new hotness.
If we had spent any real time planning this project beyond a very basic understanding of its scope and keeping it as sort of an ‘idea bucket’ that work would have been completely wasted. As it stands, no harm no foul.
The Lie
The last part of the continuum I want to address is what we have affectionately dubbed “The Lie”. This is the point past which any projections you make on time/cost/when/where/who/how something will get done may as well have come from a magic 8 ball. When asked for this type of long-long-range (usually this is somewhere in the neighborhood of 6 months from now for us) information, we play it straight up. We say “this is a lie. what we are about to say will not come true at all.” For some reason we can get stakeholders to accept and understand that it’s a lie, but we cannot get them to stop asking for the lie. It boggles the mind. But whatever. We’re up front about it, and we refuse to be held to it. Part of effective planning is identifying the issues and constraints that will make the plan go astray, presenting those, and sticking to your guns when they happen.
As a side note, I want to point out that these time thresholds we have come up with have been a moving target, and yours will differ based on the size of your team, how fast they work, the nature of your organization, and a ton of other factors. So just be prepared to experiment.
Technorati Tags:
how we do it, improvement, lean, management, quality, software, team, planning
Attribution and Analogy
Brief pause to correct and address a couple of things.
In my post Quit Living in the Past – Practices Evolve I used an analogy about hand washing in hospitals. It was later brought to my attention that Uncle Bob used this analogy (though not in exactly the depth that I did) on both a Hanselminutes Podcast episode and in a blog post a few years ago. I can honestly say I hadn’t listened to the podcast, and I may or may not have read the blog post, who knows? I did reply in my comments that it’s quite possible that this analogy was floating around out there due to Uncle Bob or others, or I had seen it in passing on twitter, or picked it up in a blog somewhere, and that is why it occurred to me to use it. So, officially, my apologies to anyone who thinks I have stolen this analogy without attributing the source. It was unintentional at worst, and I hope you’ll give me the benefit of the doubt on this one.
In my post Well-constructed != Over-architected, I opened with a story about a dog house. An anonymous commenter (since removed) accused me of stealing this one from Steve McConnell and pointed me to this CodingHorror post.
1) I’ve never read the book Rapid Development. b) I don’t read CodingHorror, and if I had this post is over 4 years old. iii) it isn’t even the same analogy. Get over it.
People wonder why sometimes I might treat some comments, particularly from those I don’t know, as trolls. Frankly, it’s because of crap like this. Analogies are analogies, and we shouldn’t be expected to see if anyone has ever used a similar analogy ever before putting one online. In the case of the handwashing one, I realize that it’s awful similar and so like I said, my apologies for not attributing. It was an awareness thing. In the dog house case, well, give me a break. If you can’t add to the conversation, don’t post a comment on something so frivolous. And if you feel like you must point out something like this (and feel free, please, if it’s valid, as is the handwashing analogy case) then don’t be a dick about it, and even if you must be a jerk, at least have the courage to use your name.
subscribe via RSS